2026年AI人物搜索的表现如何?我们构建了一个开源基准测试来找出答案。119个真实查询,来源于招聘、销售和研究领域的实际工作流程——针对四个平台进行了测试:Lessie、Exa、Claude Code和Juicebox。每个结果都通过实时网络源进行了独立验证。没有自报数据。没有精心挑选的示例。这个AI人物搜索基准测试旨在提供最客观的评估。
结果显示:Lessie总分达到65.2,在所有四个场景类别中均处于领先地位。排名第二的平台得分为55。本文将详细介绍完整的基准测试结果——我们测量了什么,如何评分,以及数据揭示了AI人物搜索的现状。
为何AI人物搜索基准测试如此重要
AI人物搜索正成为招聘、销售和研究团队的核心基础设施。但在此之前,没有标准化的方法来比较各个平台。供应商自报的准确性数据无法验证。案例研究只挑选最好的结果。这个AI人物搜索基准测试改变了这一切——119个真实查询,独立的网络验证,为所有测试平台提供了公平的竞争环境。
平台比较:AI人物搜索表现
119个真实查询,通过网络验证独立评分,范围为0–100分。每个平台在相同条件下运行相同的查询。分数通过三个维度进行平均:相关性、覆盖率和实用性。Lessie在AI人物搜索方面表现突出。
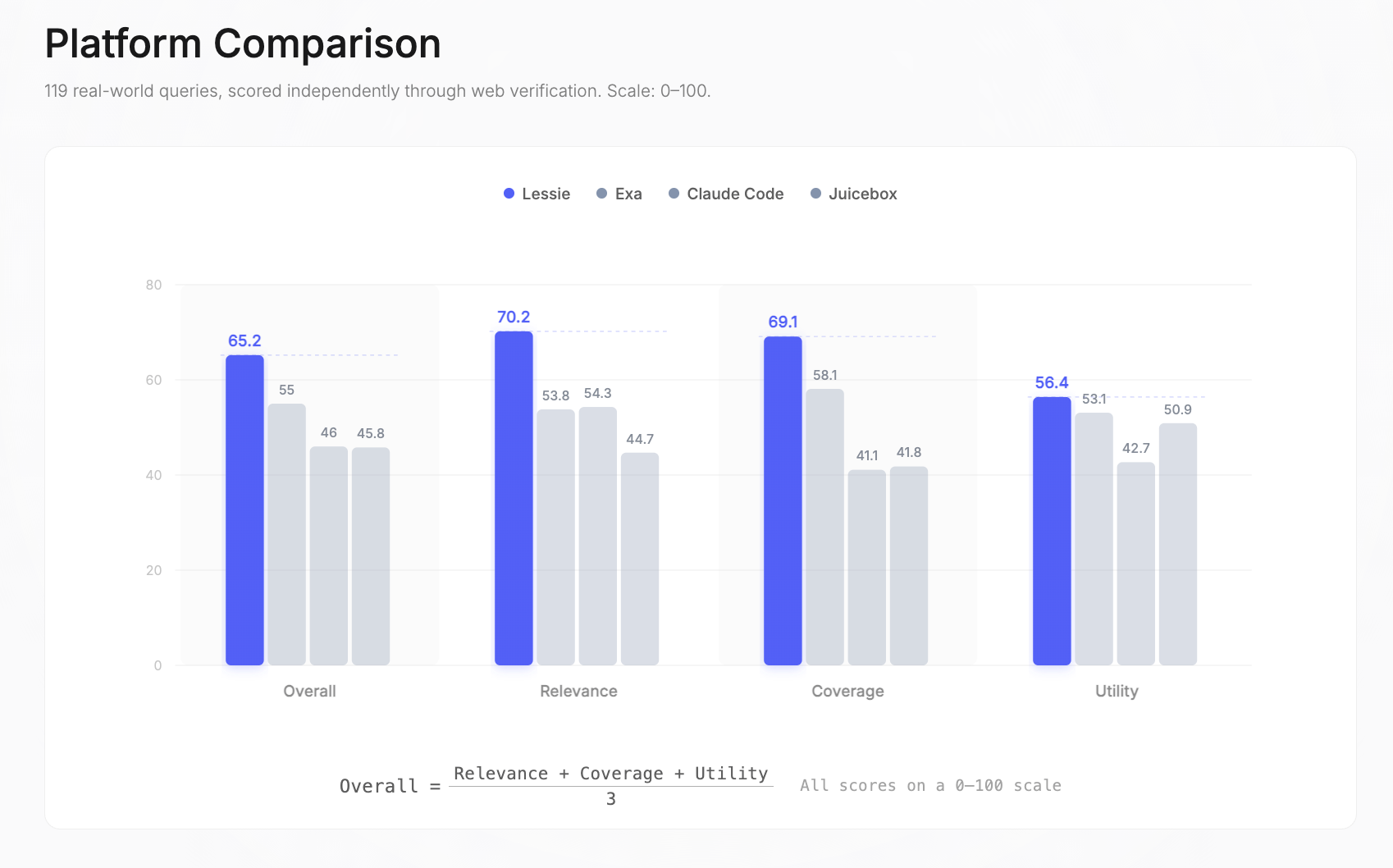
总分: Lessie 65.2 | Exa 55 | Claude Code 46 | Juicebox 45.8。总分是相关性、覆盖率和实用性的简单平均值——每个维度都独立测量,范围为0–100分。
按维度细分:Lessie在相关性(70.2 vs. 第二名54.3)、覆盖率(69.1 vs. 58.1)和实用性(56.4 vs. 53.1)方面均处于领先地位。最大的差距体现在相关性上——比第二名高出29%——这意味着Lessie在各种查询类型中始终如一地返回正确的人员,并正确排名。这充分展现了Lessie在AI人物搜索领域的优势。
按场景划分的AI人物搜索性能
基准测试涵盖了AI人物搜索创造商业价值的四个真实用例。每个场景都反映了独特的工作流程:不同的数据源、不同的标准复杂性以及对“好”结果的不同定义。
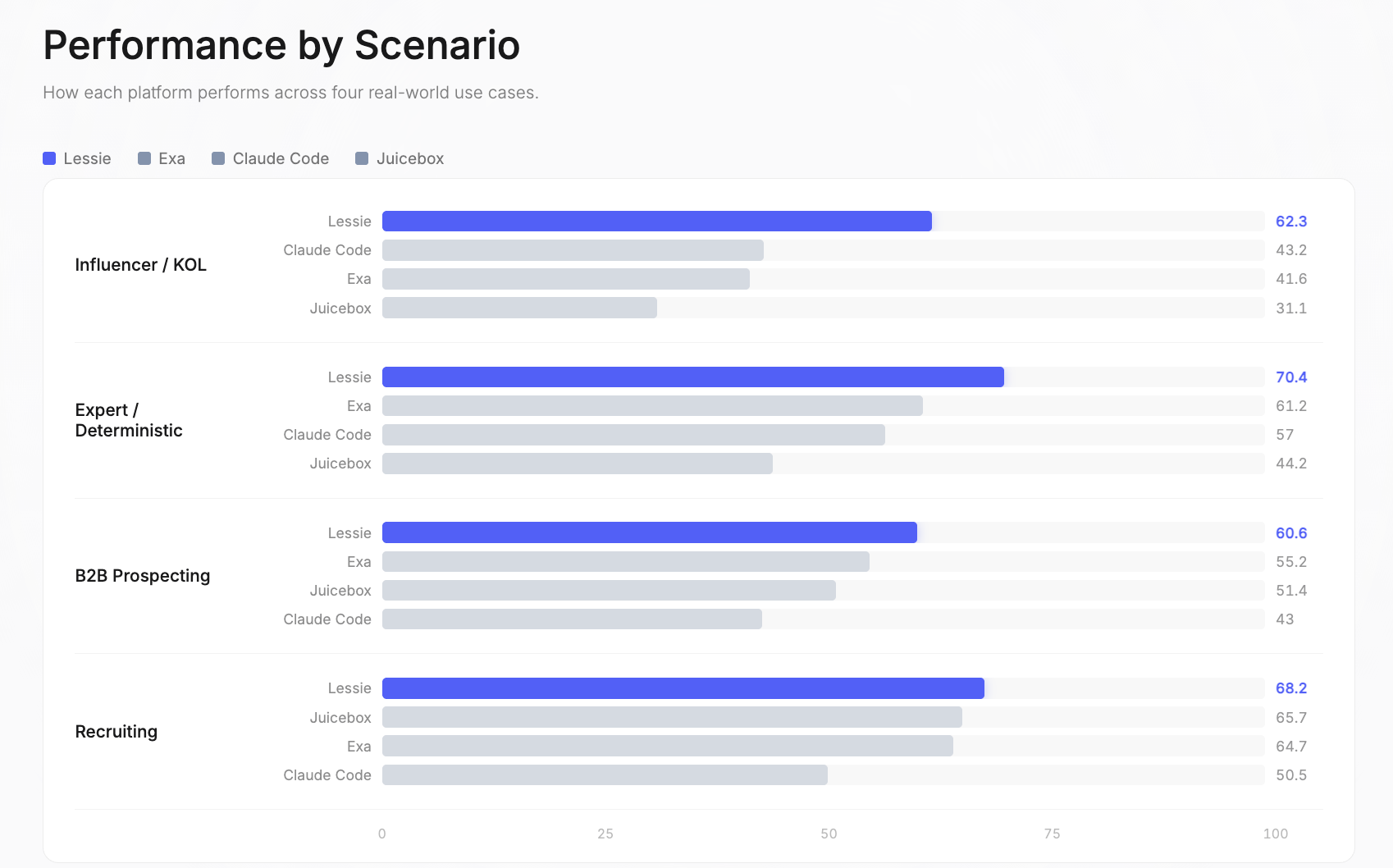
网红 / KOL: Lessie 62.3 | Claude Code 43.2 | Exa 41.6 | Juicebox 31.1。这是整个基准测试中性能差距最大的地方。单一来源平台在此处表现最差,因为网红存在于分散的社交平台——Instagram、TikTok、YouTube、Twitter、播客、新闻通讯——并且没有一个单一数据库能涵盖所有这些平台。Lessie的AI人物搜索能力在此类复杂场景中表现出色。
专家 / 确定性: Lessie 70.4 | Exa 61.2 | Claude Code 57 | Juicebox 44.2。这些查询有可验证的正确答案或寻求特定的领域专家。Lessie的混合搜索策略——结合结构化数据库和实时网络研究——被证明在寻找确切的正确人员方面最有效。这体现了Lessie在AI人物搜索中的精准性。
B2B客户开发: Lessie 60.6 | Exa 55.2 | Juicebox 51.4 | Claude Code 43。在目标公司中寻找决策者是最常见的AI人物搜索用例。Lessie的优势在于交叉引用多个数据源以验证当前职位和联系信息。
招聘: Lessie 68.2 | Juicebox 65.7 | Exa 64.7 | Claude Code 50.5。这是最具竞争力的场景——三个平台总分均高于64。招聘查询受益于以LinkedIn为中心的数据库,所有平台都可以访问。此处的差距是基准测试中最微小的。Lessie的AI人物搜索在招聘领域依然领先。
场景深度解析:AI人物搜索的细节
每个场景分数都分解为三个独立维度:相关性(是否找到了正确的人?)、覆盖率(有多少合格结果?)和实用性(返回的数据是否可操作?)。以下是详细的分解。
网红 / KOL——在社交平台中寻找内容创作者
- Lessie: 相关性 65.2,覆盖率 62.8,实用性 58.9——100%完成率
- Exa:Lessie性能的89.7%
- Claude Code:Lessie性能的82.8%
- Juicebox:Lessie性能的79.3%
专家 / 确定性——具有可验证答案或寻求特定领域专家的查询
- Lessie: 相关性 79,覆盖率 75.2,实用性 57.1——100%完成率
- Exa:Lessie性能的96.4%
- Claude Code:100%完成率但总分较低
- Juicebox:Lessie性能的71.4%
B2B客户开发——在目标公司中寻找决策者
- Lessie: 相关性 62.8,覆盖率 63.5,实用性 55.5——100%完成率
- Exa:100%完成率,覆盖率接近
- Juicebox:Lessie性能的84.4%
- Claude Code:75%完成率——此类别中最低
招聘——寻找具有特定技能、经验和地点的候选人
- Lessie: 相关性 74.8,覆盖率 75.6,实用性 54.3——100%完成率
- Exa, Juicebox:均100%完成率
- Claude Code:90%完成率
- 招聘在所有平台中获得了最高的绝对分数——这是AI人物搜索最成熟的用例
评估数据集:AI人物搜索的真实场景
基准测试使用了119个查询,这些查询来自招聘、销售和研究领域的实际从业者工作流程。这些不是合成测试用例——它们反映了专业人士在寻找人员时实际运行的搜索。数据集是多语言的(英语、葡萄牙语、西班牙语、荷兰语),并由从业者驱动。
- 招聘(30个查询): 寻找具有特定技能、经验水平和地点的候选人
- B2B客户开发(32个查询): 识别目标公司的决策者以进行销售外联
- 专家 / 确定性(28个查询): 具有可验证正确答案或寻求特定领域专家的查询
- 网红 / KOL(29个查询): 按利基、受众和参与度在社交平台中寻找内容创作者
三个评估维度衡量搜索质量的独立方面:相关性(排名质量)、覆盖率(结果数量)和实用性(数据完整性)。这些维度结合起来构成了总分。Lessie的AI人物搜索在这些方面都表现出色。
方法论:AI人物搜索的评估标准
评估流程是全自动且可复现的。每个平台返回的每个结果都通过实时网络源进行验证——没有自报数据,没有手动筛选。
步骤1:分解查询。 像“柏林一家B轮初创公司的资深机器学习工程师”这样的查询会分解为结构化的清单:角色、资历、领域、公司阶段、地点。这种分解定义了每个结果的评分标准。这是AI人物搜索的关键一步。
步骤2:通过网络验证。 每个平台返回的每个人员都通过LinkedIn、公司网站和社交资料进行检查。没有自报数据——只有可以在线独立确认的信息。这消除了平台偏见,确保了公平比较。
步骤3:在三个轴上评分。 相关性(是否找到了正确的人?)、覆盖率(有多少?)和实用性(个人资料数据是否真正有用?)。这三个分数结合成一个总分:(相关性 + 覆盖率 + 实用性)/ 3。
我们衡量什么
相关性——Padded nDCG@10。 衡量返回的人员是否与查询匹配并正确排名。每个人员都经过网络验证并根据明确标准进行评分。分数填充到10个槽位——返回较少结果会受到惩罚。这奖励了顶部结果的精确度和召回率。Lessie在AI人物搜索的相关性方面表现卓越。
覆盖率——TCR × Yield。 衡量每个查询找到的合格人员数量。结合任务完成率(平台是否返回了任何结果?)和平均合格结果产出,上限为K=10。这奖励了相关结果的可靠性和数量。
实用性——(C + E + A) / 3。 衡量返回的数据是否完整和可操作。平均三个子维度:结构完整性(C)、查询特定证据(E)和可操作性(A)。一个只有姓名但没有电子邮件、职位或公司信息的个人资料,即使该人员相关,其实用性得分也会很低。
主要发现:AI人物搜索的未来趋势
在119个查询的476次平台运行之后,出现了几个模式,揭示了AI人物搜索的现状以及每个平台的优缺点。
- 在所有四个场景中均排名第一。 Lessie是唯一在所有类别中均处于领先地位的平台——招聘、B2B客户开发、专家/确定性搜索和网红/KOL。没有其他平台在超过一个场景中排名第一。
- 100%完成率。 每个查询都返回了结果。没有其他平台达到这一点——尤其是在其他平台一无所获的利基和抽象搜索中。返回零结果是单一来源平台特有的失败模式。
- 最大的相关性差距:70.2 vs. 54.3 (+29%)。 排名质量差异在多标准查询上最为明显——结合了角色、资历、行业和地点限制的搜索。Lessie的AI人物搜索能力在此处表现突出。
- 网红是差距最大的领域。 Lessie总分62.3;第二名得分43.2。单一来源平台在此处表现最差,因为网红数据分散在数十个社交平台中。
- 实用性是竞争最激烈的领域。 个人资料数据完整性是竞争最激烈的维度——所有平台得分都在42.7到56.4之间。这是行业最有改进空间的地方。
- 招聘最具竞争力。 三个平台总分均高于64。这是现有工具表现最好的场景——也是差距最小的地方。以LinkedIn为中心的数据为所有平台提供了更强的基线。
开源: 完整的评估数据集、评分方法和平台级结果均可供审查。我们相信透明的基准测试能推动整个行业向前发展。