Wie gut ist die KI-Personensuche im Jahr 2026? Wir haben einen Open-Source-Benchmark erstellt, um das herauszufinden. 119 reale Anfragen, die aus tatsächlichen Arbeitsabläufen von Praktikern in den Bereichen Recruiting, Vertrieb und Forschung stammen — getestet auf vier Plattformen: Lessie, Exa, Claude Code und Juicebox. Jedes Ergebnis wurde unabhängig anhand von Live-Webquellen verifiziert. Keine selbst gemeldeten Daten. Keine handverlesenen Beispiele.
Das Ergebnis: Lessie erreichte insgesamt 65,2 Punkte und führte in allen vier Szenario-Kategorien der KI-Personensuche. Die nächstbeste Plattform erreichte 55 Punkte. Dieser Beitrag erläutert die vollständigen Benchmark-Ergebnisse — was wir gemessen, wie wir bewertet und was die Daten über den Stand der KI-gestützten Personensuche aussagen.
Warum dieser Benchmark zur KI-Personensuche wichtig ist
Die KI-Personensuche wird zu einer Kerninfrastruktur für Recruiting-, Vertriebs- und Forschungsteams. Doch bisher gab es keine standardisierte Methode, um Plattformen zu vergleichen. Anbieter melden selbst Genauigkeitszahlen, die nicht überprüft werden können. Fallstudien wählen die besten Ergebnisse aus. Dieser Benchmark ändert das — 119 reale Anfragen, unabhängige Web-Verifizierung und gleiche Bedingungen für jede getestete Plattform der KI-Personensuche.
Plattformvergleich der KI-Personensuche
119 reale Anfragen, unabhängig durch Web-Verifizierung auf einer Skala von 0–100 bewertet. Jede Plattform führte die gleichen Anfragen unter identischen Bedingungen aus. Die Bewertungen sind über drei Dimensionen gemittelt: Relevanz, Abdeckung und Nutzen.
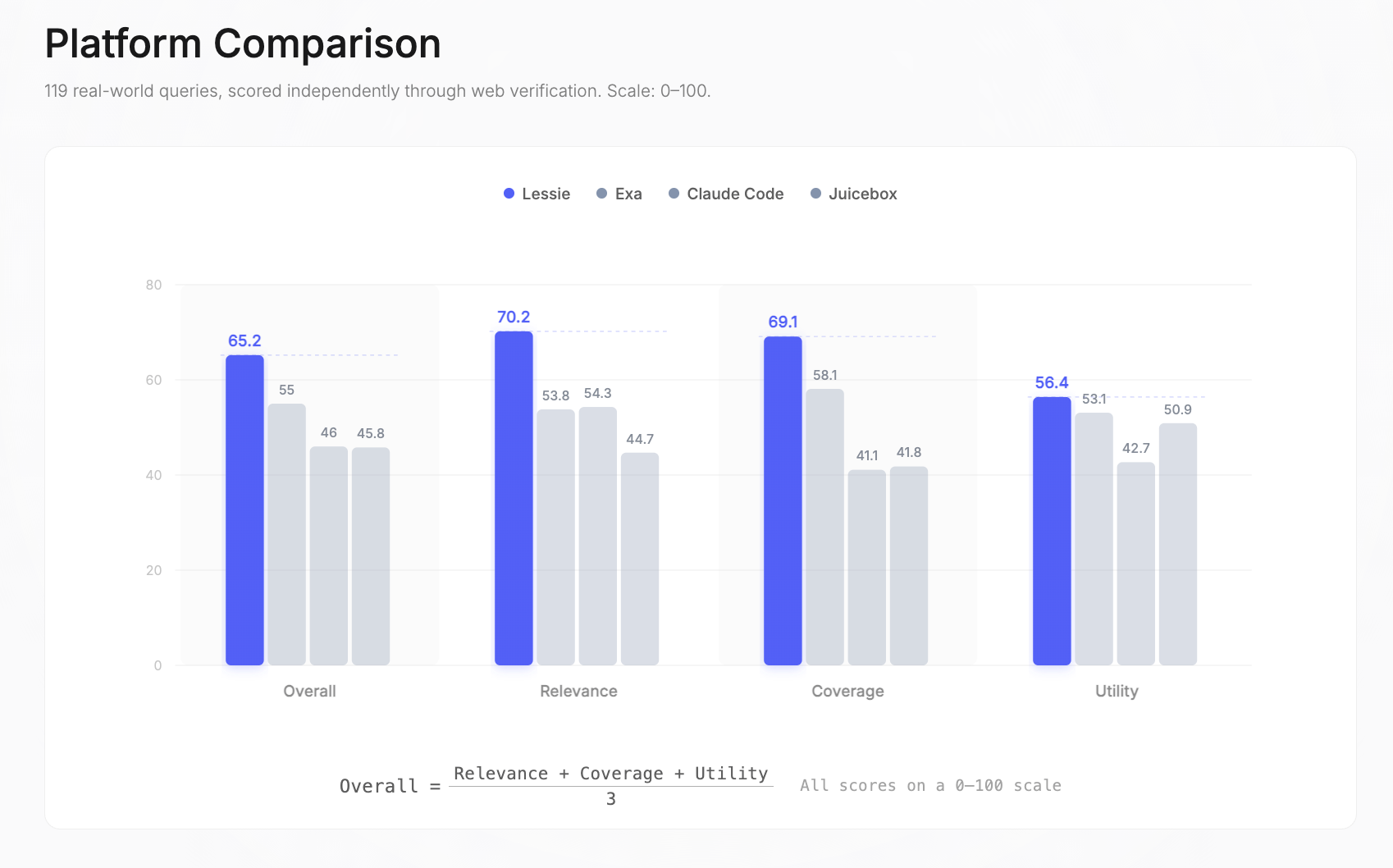
Gesamtpunktzahlen der KI-Personensuche: Lessie 65,2 | Exa 55 | Claude Code 46 | Juicebox 45,8. Die Gesamtpunktzahl ist der einfache Durchschnitt von Relevanz, Abdeckung und Nutzen — jeweils unabhängig auf einer Skala von 0–100 gemessen.
Aufgeschlüsselt nach Dimensionen: Lessie führte bei der Relevanz (70,2 vs. 54,3 für den Nächstbesten), Abdeckung (69,1 vs. 58,1) und Nutzen (56,4 vs. 53,1). Der größte Unterschied lag in der Relevanz — ein +29% Vorteil gegenüber dem Zweitplatzierten — was bedeutet, dass Lessie bei verschiedenen Anfragetypen konstant die richtigen Personen, korrekt gerankt, zurückgab.
Leistung nach Szenario der KI-Personensuche
Der Benchmark deckt vier reale Anwendungsfälle ab, in denen die KI-Personensuche einen geschäftlichen Mehrwert schafft. Jedes Szenario spiegelt einen unterschiedlichen Arbeitsablauf wider: verschiedene Datenquellen, unterschiedliche Kriteriengröße und unterschiedliche Definitionen eines „guten“Ergebnisses.
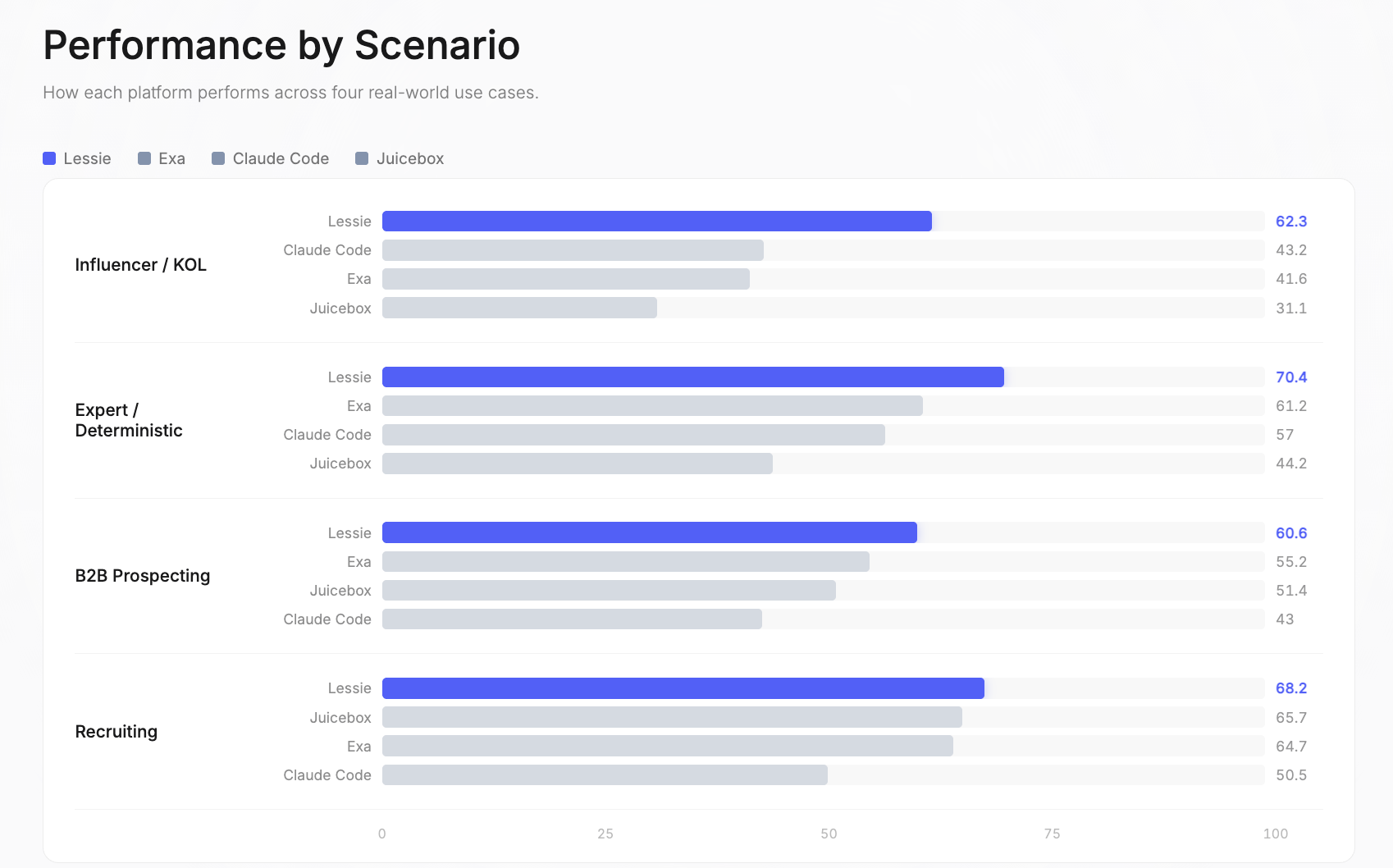
Influencer / KOL: Lessie 62,3 | Claude Code 43,2 | Exa 41,6 | Juicebox 31,1. Dies war der größte Leistungsunterschied im gesamten Benchmark der KI-Personensuche. Plattformen mit einer einzigen Quelle haben hier die größten Schwierigkeiten, da Influencer auf fragmentierten sozialen Plattformen existieren — Instagram, TikTok, YouTube, Twitter, Podcasts, Newsletter — und keine einzelne Datenbank sie alle abdeckt.
Experte / Deterministisch: Lessie 70,4 | Exa 61,2 | Claude Code 57 | Juicebox 44,2. Diese Anfragen haben überprüfbare korrekte Antworten oder suchen spezifische Fachexperten. Lessies hybride Suchstrategie — die Kombination von strukturierten Datenbanken mit Live-Web-Recherche — erwies sich als am effektivsten, um genau die richtigen Personen zu finden.
B2B-Akquise: Lessie 60,6 | Exa 55,2 | Juicebox 51,4 | Claude Code 43. Das Finden von Entscheidungsträgern in Zielunternehmen ist der häufigste Anwendungsfall der KI-Personensuche. Lessies Vorteil ergibt sich aus dem Abgleich mehrerer Datenquellen, um aktuelle Rollen und Kontaktinformationen zu überprüfen.
Recruiting: Lessie 68,2 | Juicebox 65,7 | Exa 64,7 | Claude Code 50,5. Dies war das wettbewerbsintensivste Szenario — drei Plattformen erzielten insgesamt über 64 Punkte. Recruiting-Anfragen profitieren von LinkedIn-zentrierten Datenbanken, auf die alle Plattformen zugreifen. Die Margen sind hier die geringsten im Benchmark.
Szenario-Detailanalyse der KI-Personensuche
Jede Szenario-Bewertung gliedert sich in drei unabhängige Dimensionen: Relevanz (wurden die richtigen Personen gefunden?), Abdeckung (wie viele qualifizierte Ergebnisse?) und Nutzen (sind die zurückgegebenen Daten verwertbar?). Hier ist die detaillierte Aufschlüsselung.
Influencer / KOL—Content-Ersteller auf sozialen Plattformen finden
- Lessie: Relevanz 65,2, Abdeckung 62,8, Nutzen 58,9—100% Abschlussrate
- Exa: 89,7% der Lessie-Leistung
- Claude Code: 82,8% der Lessie-Leistung
- Juicebox: 79,3% der Lessie-Leistung
Experte / Deterministisch—Anfragen mit überprüfbaren Antworten oder spezifischen Fachexperten
- Lessie: Relevanz 79, Abdeckung 75,2, Nutzen 57,1—100% Abschlussrate
- Exa: 96,4% der Lessie-Leistung
- Claude Code: 100% Abschlussrate, aber niedrigere Gesamtpunktzahlen
- Juicebox: 71,4% der Lessie-Leistung
B2B-Akquise—Entscheidungsträger in Zielunternehmen finden
- Lessie: Relevanz 62,8, Abdeckung 63,5, Nutzen 55,5—100% Abschlussrate
- Exa: 100% Abschlussrate, nah an der Abdeckung
- Juicebox: 84,4% der Lessie-Leistung
- Claude Code: 75% Abschlussrate—die niedrigste in dieser Kategorie
Recruiting—Kandidaten mit spezifischen Fähigkeiten, Erfahrungen und Standorten finden
- Lessie: Relevanz 74,8, Abdeckung 75,6, Nutzen 54,3—100% Abschlussrate
- Exa, Juicebox: beide 100% Abschlussrate
- Claude Code: 90% Abschlussrate
- Recruiting hatte die höchsten absoluten Punktzahlen über alle Plattformen hinweg—dies ist der reifste Anwendungsfall für die KI-Personensuche
Evaluierungsdatensatz
Der Benchmark verwendet 119 Anfragen, die aus realen Arbeitsabläufen von Praktikern in den Bereichen Recruiting, Vertrieb und Forschung stammen. Dies sind keine synthetischen Testfälle—sie spiegeln die tatsächlichen Suchen wider, die Fachleute durchführen, wenn sie nach Personen suchen. Der Datensatz ist mehrsprachig (Englisch, Portugiesisch, Spanisch, Niederländisch) und praxisorientiert.
- Recruiting (30 Anfragen): Kandidaten mit spezifischen Fähigkeiten, Erfahrungsstufen und Standorten finden
- B2B-Akquise (32 Anfragen): Entscheidungsträger in Zielunternehmen für die Vertriebsansprache identifizieren
- Experte / Deterministisch (28 Anfragen): Anfragen mit überprüfbaren korrekten Antworten oder Suche nach spezifischen Fachexperten
- Influencer / KOL (29 Anfragen): Content-Ersteller auf sozialen Plattformen nach Nische, Zielgruppe und Engagement finden
Drei Bewertungsdimensionen messen unabhängige Aspekte der Suchqualität der KI-Personensuche: Relevanz (Ranking-Qualität), Abdeckung (Ergebnisvolumen) und Nutzen (Datenvollständigkeit). Diese ergeben zusammen die Gesamtpunktzahl.
Methodik der KI-Personensuche
Die Evaluierungspipeline ist vollautomatisiert und reproduzierbar. Jedes Ergebnis jeder Plattform wird anhand von Live-Webquellen verifiziert—keine selbst gemeldeten Daten, keine manuelle Kuration.
Schritt 1: Die Anfrage zerlegen. Eine Anfrage wie „Senior ML Engineer bei einem Series B Startup in Berlin“ wird zu einer strukturierten Checkliste: Rolle, Seniorität, Domäne, Unternehmensphase, Standort. Diese Zerlegung definiert die Bewertungskriterien für jedes Ergebnis.
Schritt 2: Im Web überprüfen. Jede von jeder Plattform zurückgegebene Person wird mit LinkedIn, Unternehmenswebsites und sozialen Profilen abgeglichen. Keine selbst gemeldeten Daten — nur das, was online unabhängig bestätigt werden kann. Dies eliminiert Plattform-Bias und gewährleistet einen fairen Vergleich der KI-Personensuche.
Schritt 3: Nach drei Achsen bewerten. Relevanz (wurden die richtigen Personen gefunden?), Abdeckung (wie viele?) und Nutzen (sind die Profildaten tatsächlich nützlich?). Diese drei Scores ergeben zusammen eine Gesamtpunktzahl: (Relevanz + Abdeckung + Nutzen) / 3.
Was wir messen
Relevanz—Padded nDCG@10. Misst, ob die zurückgegebenen Personen der Anfrage entsprechen und korrekt gerankt sind. Jede Person wird web-verifiziert und nach expliziten Kriterien bewertet. Die Punktzahl wird auf 10 Slots aufgefüllt—die Rückgabe weniger Ergebnisse wird bestraft. Dies belohnt sowohl Präzision als auch Recall in den Top-Ergebnissen.
Abdeckung—TCR × Yield. Misst, wie viele qualifizierte Personen pro Anfrage gefunden werden. Kombiniert die Aufgabenabschlussrate (hat die Plattform überhaupt Ergebnisse geliefert?) mit der durchschnittlichen Ausbeute an qualifizierten Ergebnissen, begrenzt auf K=10. Dies belohnt sowohl die Zuverlässigkeit als auch das Volumen relevanter Ergebnisse.
Nutzen—(C + E + A) / 3. Misst, ob die zurückgegebenen Daten vollständig und verwertbar sind. Mittelt drei Unterdimensionen: strukturelle Vollständigkeit (C), anfragespezifische Evidenz (E) und Verwertbarkeit (A). Ein Profil mit einem Namen, aber ohne E-Mail, Titel oder Unternehmen erzielt einen niedrigen Nutzenwert, selbst wenn die Person relevant ist.
Wichtige Erkenntnisse zur KI-Personensuche
Nach 476 Plattformläufen über 119 Anfragen hinweg zeigten sich mehrere Muster, die den heutigen Stand der KI-Personensuche und die Stärken oder Schwächen jeder Plattform aufzeigen.
- #1 in allen vier Szenarien. Lessie ist die einzige Plattform, die in jeder Kategorie führt—Recruiting, B2B-Akquise, Experte / Deterministisch und Influencer / KOL. Keine andere Plattform rangierte in mehr als einem Szenario auf Platz eins.
- 100% Abschlussrate. Jede Anfrage lieferte Ergebnisse. Keine andere Plattform erreichte dies—insbesondere bei Nischen- und abstrakten Suchen, bei denen andere nichts fanden. Das Zurückgeben von null Ergebnissen ist ein Fehlerfall, der für Single-Source-Plattformen einzigartig ist.
- Größter Relevanz-Unterschied: 70,2 vs. 54,3 (+29%). Der Unterschied in der Ranking-Qualität ist bei Multi-Kriterien-Anfragen am ausgeprägtesten—Suchen, die Rollen-, Senioritäts-, Branchen- und Standortbeschränkungen kombinieren.
- Influencer ist der größte Unterschied. Lessie erzielte insgesamt 62,3 Punkte; der Zweitplatzierte erreichte 43,2 Punkte. Single-Source-Plattformen haben hier die größten Schwierigkeiten, da Influencer-Daten über Dutzende von sozialen Plattformen fragmentiert sind.
- Nutzen ist das engste Rennen. Die Vollständigkeit der Profildaten ist die wettbewerbsintensivste Dimension—alle Plattformen erzielten zwischen 42,7 und 56,4 Punkte. Hier hat die Branche den größten Verbesserungsbedarf.
- Recruiting ist am wettbewerbsintensivsten. Drei Plattformen erzielten insgesamt über 64 Punkte. Dies ist das Szenario, in dem bestehende Tools am besten abschneiden—und in dem die Margen am geringsten sind. LinkedIn-zentrierte Daten geben allen Plattformen hier eine stärkere Basis.
Open Source: Der vollständige Evaluierungsdatensatz, die Bewertungsmethodik und die plattformspezifischen Ergebnisse stehen zur Überprüfung bereit. Wir glauben, dass transparente Benchmarks die gesamte Branche voranbringen.