2026年のAI人物検索はどれほど優れているのでしょうか?私たちはそれを明らかにするために、オープンソースのベンチマークを構築しました。採用、営業、研究における実際の業務フローから抽出された119件のリアルなクエリを、Lessie、Exa、Claude Code、Juiceboxの4つのプラットフォームでテストしました。すべての結果は、ライブのウェブソースに対して独立して検証されました。自己申告データや、都合の良い例は一切ありません。
その結果、Lessieは総合65.2点を獲得し、4つのシナリオカテゴリすべてでリードしました。次に近いプラットフォームは55点でした。この記事では、このAI人物検索ベンチマークの全結果—何を測定し、どのように採点し、データがAIを活用した人物検索の現状について何を明らかにしているのか—を詳しく説明します。
このAI人物検索ベンチマークが重要な理由
AI人物検索は、採用、営業、研究チームにとって中核的なインフラとなりつつあります。しかし、これまでプラットフォームを比較する標準的な方法はありませんでした。ベンダーは検証できない精度数値を自己申告し、ケーススタディでは都合の良い結果だけを取り上げていました。このAI人物検索ベンチマークはそれを変えます—119件のリアルなクエリ、独立したウェブ検証、そしてテストされたすべてのプラットフォームに公平な競争の場を提供します。
プラットフォーム比較
119件のリアルなクエリを、ウェブ検証を通じて独立して0–100のスケールで採点しました。各プラットフォームは、同じ条件下で同じクエリを実行しました。スコアは、関連性、カバレッジ、有用性の3つの側面で平均化されています。
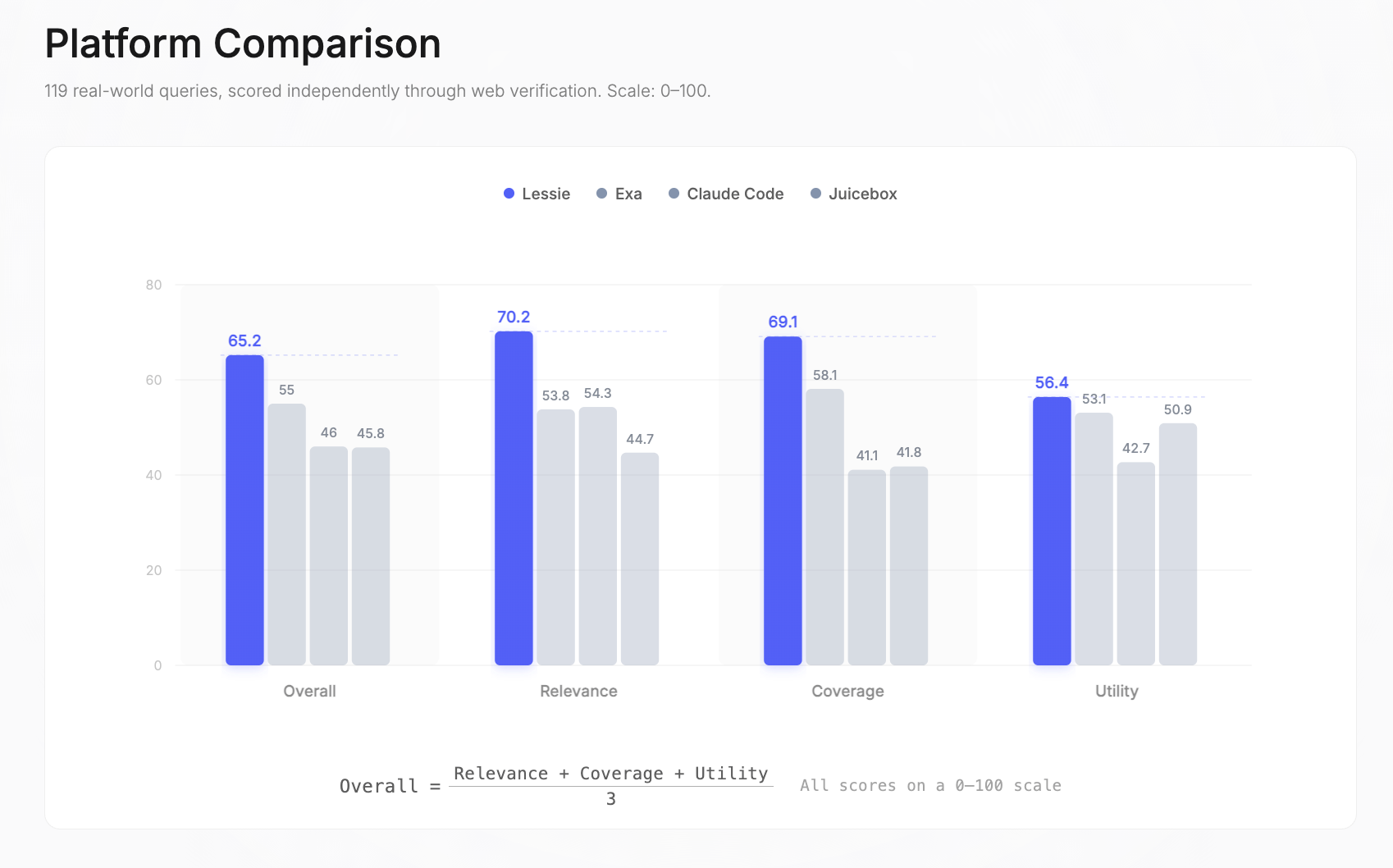
総合スコア: Lessie 65.2 | Exa 55 | Claude Code 46 | Juicebox 45.8。総合スコアは、関連性、カバレッジ、有用性の単純平均です—それぞれが0–100のスケールで独立して測定されます。
内訳を見ると、Lessieは関連性(70.2 vs. 次点54.3)、カバレッジ(69.1 vs. 58.1)、そして有用性(56.4 vs. 53.1)でリードしました。最大の差は関連性で、次点に29%の差をつけました—これは、Lessieが多様なクエリタイプにおいて、常に適切な人物を正確にランク付けして返したことを意味します。
シナリオ別パフォーマンス
このAI人物検索ベンチマークは、AI人物検索がビジネス価値を生み出す4つのリアルなユースケースをカバーしています。各シナリオは異なるワークフローを反映しており、異なるデータソース、異なる基準の複雑さ、そして「良い」結果の異なる定義を持っています。
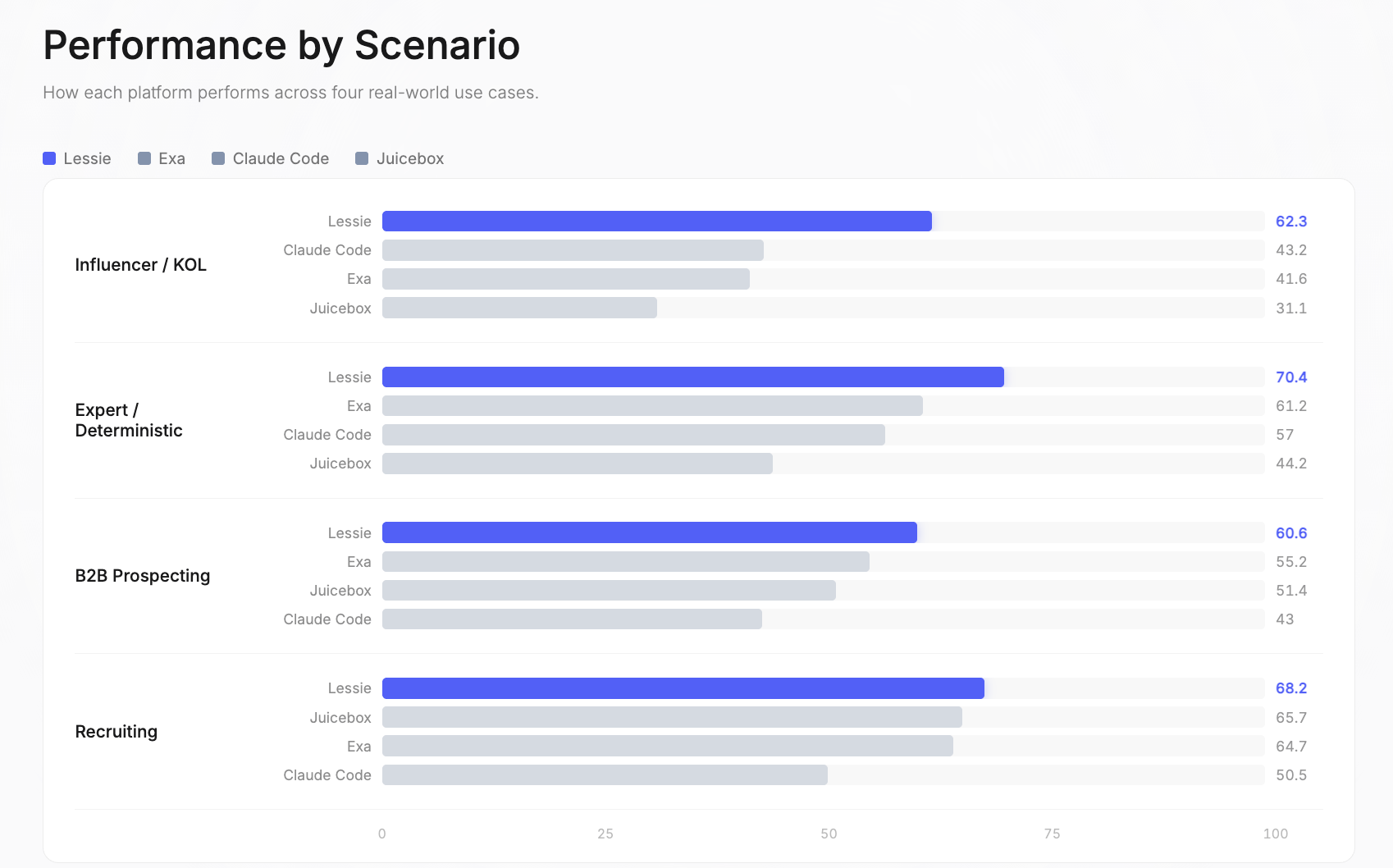
インフルエンサー / KOL: Lessie 62.3 | Claude Code 43.2 | Exa 41.6 | Juicebox 31.1。これはベンチマーク全体で最も大きなパフォーマンス差でした。インフルエンサーはInstagram、TikTok、YouTube、Twitter、ポッドキャスト、ニュースレターといった断片化されたソーシャルプラットフォームに存在するため、単一ソースのプラットフォームはここで最も苦戦します—そして、単一のデータベースではそれらすべてをカバーできません。
専門家 / 確定型: Lessie 70.4 | Exa 61.2 | Claude Code 57 | Juicebox 44.2。これらのクエリには検証可能な正解があるか、特定の分野の専門家を求めています。Lessieのハイブリッド検索戦略—構造化データベースとライブウェブ調査を組み合わせる—は、まさに適切な人物を見つけるのに最も効果的であることが証明されました。
B2Bプロスペクティング: Lessie 60.6 | Exa 55.2 | Juicebox 51.4 | Claude Code 43。ターゲット企業で意思決定者を見つけることは、最も一般的なAI人物検索のユースケースです。Lessieの優位性は、複数のデータソースを相互参照して現在の役職と連絡先情報を検証することにあります。
採用: Lessie 68.2 | Juicebox 65.7 | Exa 64.7 | Claude Code 50.5。これは最も競争の激しいシナリオでした—3つのプラットフォームが総合64点を超えました。採用クエリは、すべてのプラットフォームがアクセスできるLinkedIn中心のデータベースから恩恵を受けます。ここでの差は、ベンチマークの中で最も小さいものでした。
シナリオ詳細分析
各シナリオスコアは、関連性(適切な人物を見つけられたか?)、カバレッジ(どれだけの適格な結果が得られたか?)、有用性(返されたデータは実用可能か?)の3つの独立した側面で分解されます。詳細な内訳は以下の通りです。
インフルエンサー / KOL—ソーシャルプラットフォーム全体でコンテンツクリエイターを見つける
- Lessie: 関連性 65.2、カバレッジ 62.8、有用性 58.9—100%完了率
- Exa: Lessieのパフォーマンスの89.7%
- Claude Code: Lessieのパフォーマンスの82.8%
- Juicebox: Lessieのパフォーマンスの79.3%
専門家 / 確定型—検証可能な回答または特定の分野の専門家を求めるクエリ
- Lessie: 関連性 79、カバレッジ 75.2、有用性 57.1—100%完了率
- Exa: Lessieのパフォーマンスの96.4%
- Claude Code: 100%完了率だが、総合スコアは低い
- Juicebox: Lessieのパフォーマンスの71.4%
B2Bプロスペクティング—ターゲット企業で意思決定者を見つける
- Lessie: 関連性 62.8、カバレッジ 63.5、有用性 55.5—100%完了率
- Exa: 100%完了率、カバレッジは近い
- Juicebox: Lessieのパフォーマンスの84.4%
- Claude Code: 75%完了率—このカテゴリで最低
採用—特定のスキル、経験、所在地を持つ候補者を見つける
- Lessie: 関連性 74.8、カバレッジ 75.6、有用性 54.3—100%完了率
- Exa、Juicebox: 両方とも100%完了率
- Claude Code: 90%完了率
- 採用はすべてのプラットフォームで最高の絶対スコアを記録しました—これはAI人物検索にとって最も成熟したユースケースです
評価データセット
このAI人物検索ベンチマークは、採用、営業、研究における実際の業務フローから厳選された119件のクエリを使用しています。これらは人工的なテストケースではなく—プロフェッショナルが人物を探す際に実際に行う検索を反映しています。データセットは多言語(英語、ポルトガル語、スペイン語、オランダ語)で、実務家主導です。
- 採用(30件のクエリ): 特定のスキル、経験レベル、所在地を持つ候補者を見つける
- B2Bプロスペクティング(32件のクエリ): 営業アウトリーチのためにターゲット企業で意思決定者を特定する
- 専門家 / 確定型(28件のクエリ): 検証可能な正解がある、または特定の分野の専門家を求めるクエリ
- インフルエンサー / KOL(29件のクエリ): ニッチ、オーディエンス、エンゲージメントに基づいてソーシャルプラットフォーム全体でコンテンツクリエイターを見つける
3つの評価側面は、検索品質の独立した側面を測定します: 関連性(ランキング品質)、カバレッジ(結果量)、そして有用性(データ完全性)。これらが組み合わさって総合スコアとなります。
AI人物検索ベンチマークの手法
評価パイプラインは完全に自動化されており、再現可能です。すべてのプラットフォームからのすべての結果は、ライブのウェブソースに対して検証されます—自己申告データや手動キュレーションは一切ありません。
ステップ1: クエリを分解する。「ベルリンのシリーズBスタートアップのシニアMLエンジニア」のようなクエリは、役割、役職、ドメイン、企業ステージ、所在地といった構造化されたチェックリストになります。この分解が、各結果の採点基準を定義します。
ステップ2: ウェブに対して検証する。すべてのプラットフォームから返されたすべての人物は、LinkedIn、企業ウェブサイト、ソーシャルプロフィールに対してチェックされます。自己申告データは一切ありません—オンラインで独立して確認できるもののみです。これにより、プラットフォームの偏りが排除され、公平な比較が保証されます。
ステップ3: 3つの軸で採点する。関連性(適切な人物を見つけられたか?)、カバレッジ(何人見つけられたか?)、有用性(プロフィールデータは実際に役立つか?)。これら3つのスコアが組み合わさって1つの総合スコアになります: (関連性 + カバレッジ + 有用性)/ 3。
測定項目
関連性—Padded nDCG@10。返された人物がクエリと一致し、正しくランク付けされているかを測定します。各人物はウェブ検証され、明示的な基準に対して採点されます。スコアは10スロットにパディングされます—結果が少ない場合はペナルティが課されます。これにより、上位結果における精度と再現性の両方が評価されます。
カバレッジ—TCR × Yield。クエリごとにどれだけの適格な人物が見つかるかを測定します。タスク完了率(プラットフォームが何らかの結果を返したか?)と、K=10に制限された平均適格結果数を組み合わせます。これにより、信頼性と関連性の高い結果の量の両方が評価されます。
有用性—(C + E + A) / 3。返されたデータが完全で実用可能であるかを測定します。構造的完全性(C)、クエリ固有の証拠(E)、実用性(A)の3つのサブディメンションを平均します。名前はあるがメールアドレス、役職、会社がないプロフィールは、たとえその人物が関連性があっても有用性スコアは低くなります。
主な発見
119件のクエリにわたる476回のプラットフォーム実行の後、AI人物検索の現状と、各プラットフォームがどこで優れているか、どこで劣っているかを明らかにするいくつかのパターンが浮上しました。
- 4つのシナリオすべてでNo.1。Lessieは、採用、B2Bプロスペクティング、専門家/確定型、インフルエンサー/KOLのすべてのカテゴリでリードした唯一のプラットフォームです。他のどのプラットフォームも、複数のシナリオで1位にランクインすることはありませんでした。
- 100%の完了率。すべてのクエリで結果が返されました。他のどのプラットフォームもこれを達成できませんでした—特に、他が何も返さなかったニッチで抽象的な検索において。ゼロの結果を返すことは、単一ソースのプラットフォームに特有の失敗モードです。
- 最大の関連性ギャップ: 70.2 vs. 54.3 (+29%)。ランキング品質の差は、役割、役職、業界、所在地の制約を組み合わせた多基準クエリで最も顕著です。
- インフルエンサーが最も大きなギャップ。Lessieは総合62.3点を獲得し、次点は43.2点でした。インフルエンサーデータは数十のソーシャルプラットフォームに断片化されているため、単一ソースのプラットフォームはここで最も苦戦します。
- 有用性が最も接戦。プロフィールデータの完全性は最も競争の激しい側面です—すべてのプラットフォームが42.7から56.4の間でスコアを記録しました。これは業界が最も改善の余地がある部分です。
- 採用が最も競争が激しい。3つのプラットフォームが総合64点を超えました。これは既存のツールが最も優れたパフォーマンスを発揮するシナリオであり—差が最も小さい場所です。LinkedIn中心のデータは、すべてのプラットフォームにここでより強力なベースラインを提供します。
オープンソース: 完全な評価データセット、採点方法論、プラットフォームレベルの結果はレビューのために利用可能です。私たちは、透明性のあるベンチマークが業界全体を前進させると信じています。