Quelle est la performance de la recherche de personnes par IA en 2026 ? Nous avons créé un benchmark open-source pour le découvrir. 119 requêtes réelles issues de workflows de praticiens en recrutement, vente et recherche—testées sur quatre plateformes : Lessie, Exa, Claude Code et Juicebox. Chaque résultat a été vérifié indépendamment par rapport à des sources web en direct. Pas de données auto-déclarées. Pas d\'exemples triés sur le volet.
Le résultat : Lessie a obtenu un score global de 65,2, dominant les quatre catégories de scénarios. La plateforme la plus proche a obtenu 55. Cet article détaille les résultats complets du benchmark—ce que nous avons mesuré, comment nous avons noté et ce que les données révèlent sur l\'état actuel de la recherche de personnes par IA.
Pourquoi ce benchmark est important pour la recherche de personnes par IA
La recherche de personnes par IA devient une infrastructure essentielle pour les équipes de recrutement, de vente et de recherche. Mais jusqu\'à présent, il n\'existait pas de méthode standardisée pour comparer les plateformes. Les fournisseurs auto-déclarent des chiffres de précision invérifiables. Les études de cas sélectionnent les meilleurs résultats. Ce benchmark change cela—119 requêtes réelles, une vérification web indépendante et des conditions équitables pour chaque plateforme testée en matière de recherche de personnes par IA.
Comparaison des plateformes de recherche de personnes par IA
119 requêtes réelles, évaluées indépendamment par vérification web sur une échelle de 0–100. Chaque plateforme a exécuté les mêmes requêtes dans des conditions identiques. Les scores sont une moyenne sur trois dimensions : Pertinence, Couverture et Utilité.
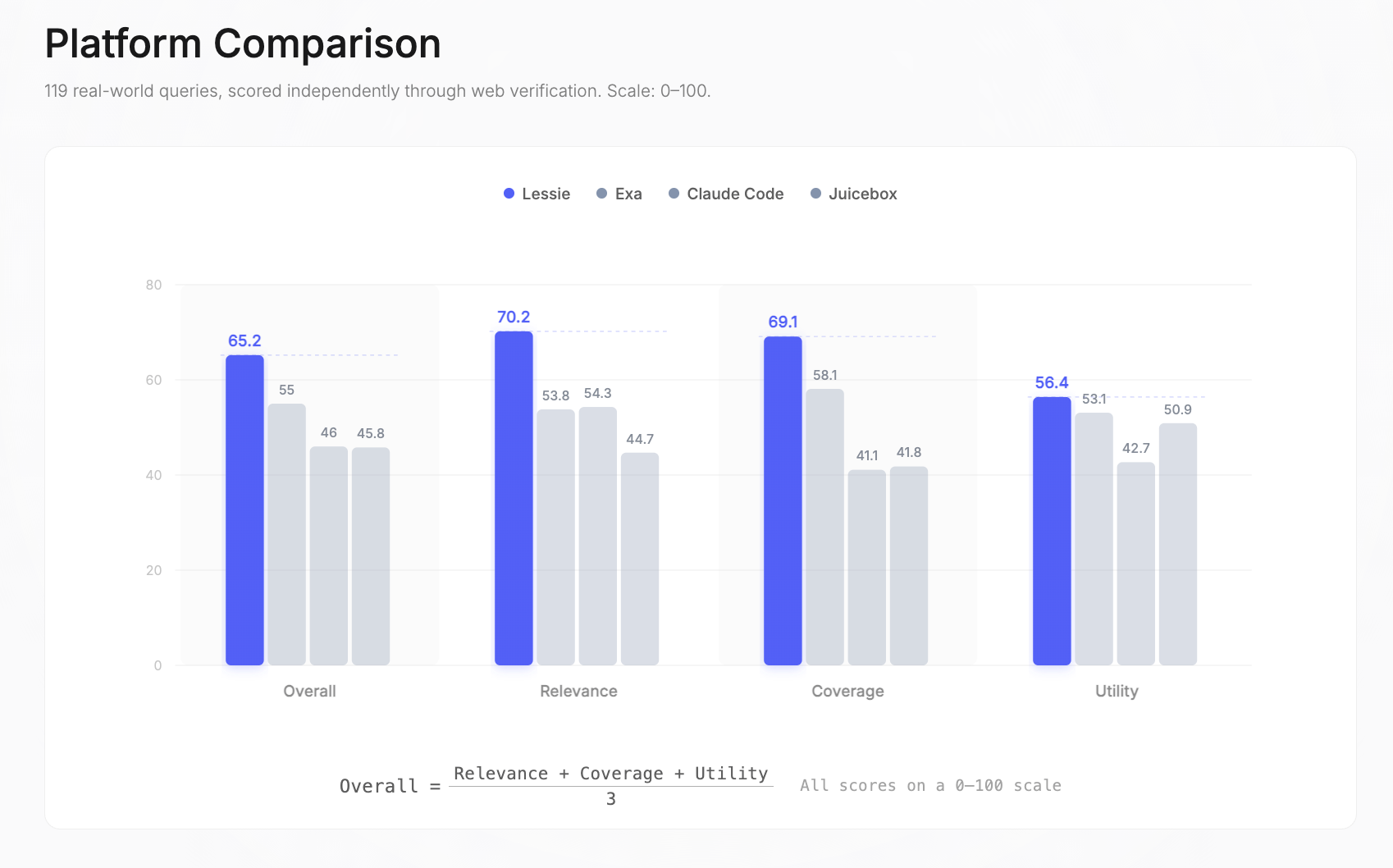
Scores globaux : Lessie 65,2 | Exa 55 | Claude Code 46 | Juicebox 45,8. Le score global est la moyenne simple de la Pertinence, de la Couverture et de l\'Utilité—chacune mesurée indépendamment sur une échelle de 0–100.
En décomposant par dimension : Lessie a dominé en Pertinence (70,2 contre 54,3 pour le suivant), en Couverture (69,1 contre 58,1) et en Utilité (56,4 contre 53,1). L\'écart le plus important était en Pertinence—un avantage de +29 % sur le second—ce qui signifie que Lessie a constamment renvoyé les bonnes personnes, correctement classées, sur divers types de requêtes de recherche de personnes par IA.
Performance par scénario de recherche de personnes par IA
Le benchmark couvre quatre cas d\'utilisation réels où la recherche de personnes par IA crée de la valeur commerciale. Chaque scénario reflète un workflow distinct : différentes sources de données, une complexité de critères différente et différentes définitions d\'un “bon” résultat.
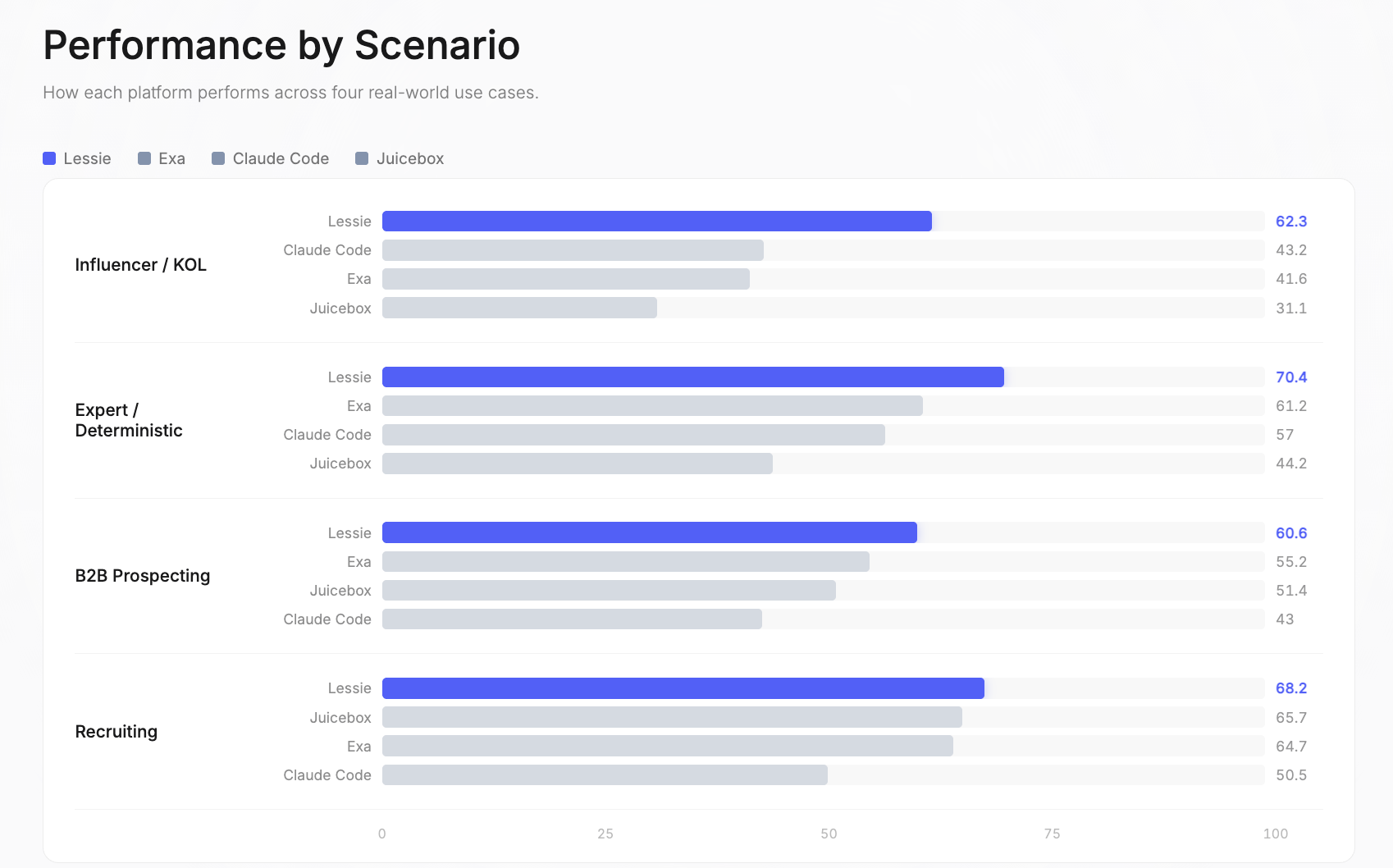
Influenceur / KOL : Lessie 62,3 | Claude Code 43,2 | Exa 41,6 | Juicebox 31,1. C\'était l\'écart de performance le plus large de tout le benchmark. Les plateformes à source unique ont le plus de mal ici car les influenceurs existent sur des plateformes sociales fragmentées—Instagram, TikTok, YouTube, Twitter, podcasts, newsletters—et aucune base de données unique ne les couvre toutes. C\'est un point fort pour la recherche de personnes par IA de Lessie.
Expert / Déterministe : Lessie 70,4 | Exa 61,2 | Claude Code 57 | Juicebox 44,2. Ces requêtes ont des réponses vérifiables ou recherchent des experts de domaine spécifiques. La stratégie de recherche hybride de Lessie—combinant des bases de données structurées avec une recherche web en direct—s\'est avérée la plus efficace pour trouver les personnes exactes. Un avantage clé pour la recherche de personnes par IA.
Prospection B2B : Lessie 60,6 | Exa 55,2 | Juicebox 51,4 | Claude Code 43. Trouver des décideurs dans les entreprises cibles est le cas d\'utilisation le plus courant de la recherche de personnes par IA. L\'avantage de Lessie vient du recoupement de multiples sources de données pour vérifier les rôles actuels et les informations de contact.
Recrutement : Lessie 68,2 | Juicebox 65,7 | Exa 64,7 | Claude Code 50,5. C\'était le scénario le plus compétitif—trois plateformes ont obtenu plus de 64 au total. Les requêtes de recrutement bénéficient des bases de données centrées sur LinkedIn, auxquelles toutes les plateformes accèdent. Les marges ici sont les plus minces du benchmark pour la recherche de personnes par IA.
Analyse approfondie des scénarios de recherche de personnes par IA
Chaque score de scénario se décompose en trois dimensions indépendantes : Pertinence (avez-vous trouvé les bonnes personnes ?), Couverture (combien de résultats qualifiés ?) et Utilité (les données renvoyées sont-elles exploitables ?). Voici la ventilation détaillée.
Influenceur / KOL—Trouver des créateurs de contenu sur les plateformes sociales
- Lessie : Pertinence 65,2, Couverture 62,8, Utilité 58,9—taux d\'achèvement de 100 %
- Exa : 89,7 % de la performance de Lessie
- Claude Code : 82,8 % de la performance de Lessie
- Juicebox : 79,3 % de la performance de Lessie
Expert / Déterministe—Requêtes avec des réponses vérifiables ou des experts de domaine spécifiques
- Lessie : Pertinence 79, Couverture 75,2, Utilité 57,1—taux d\'achèvement de 100 %
- Exa : 96,4 % de la performance de Lessie
- Claude Code : taux d\'achèvement de 100 % mais scores globaux inférieurs
- Juicebox : 71,4 % de la performance de Lessie
Prospection B2B—Trouver des décideurs dans les entreprises cibles
- Lessie : Pertinence 62,8, Couverture 63,5, Utilité 55,5—taux d\'achèvement de 100 %
- Exa : taux d\'achèvement de 100 %, proche en Couverture
- Juicebox : 84,4 % de la performance de Lessie
- Claude Code : taux d\'achèvement de 75 %—le plus bas de cette catégorie
Recrutement—Trouver des candidats avec des compétences, une expérience et une localisation spécifiques
- Lessie : Pertinence 74,8, Couverture 75,6, Utilité 54,3—taux d\'achèvement de 100 %
- Exa, Juicebox : tous deux 100 % de taux d\'achèvement
- Claude Code : 90 % de taux d\'achèvement
- Le recrutement a obtenu les scores absolus les plus élevés sur toutes les plateformes—c\'est le cas d\'utilisation le plus mature pour la recherche de personnes par IA
Jeu de données d\'évaluation pour la recherche de personnes par IA
Le benchmark utilise 119 requêtes élaborées à partir de workflows de praticiens réels en recrutement, vente et recherche. Ce ne sont pas des cas de test synthétiques—ils reflètent les recherches réelles que les professionnels effectuent lorsqu\'ils recherchent des personnes. Le jeu de données est multilingue (anglais, portugais, espagnol, néerlandais) et axé sur les praticiens.
- Recrutement (30 requêtes) : Trouver des candidats avec des compétences, des niveaux d\'expérience et des localisations spécifiques
- Prospection B2B (32 requêtes) : Identifier les décideurs dans les entreprises cibles pour la prospection commerciale
- Expert / Déterministe (28 requêtes) : Requêtes avec des réponses correctes vérifiables ou recherchant des experts de domaine spécifiques
- Influenceur / KOL (29 requêtes) : Trouver des créateurs de contenu sur les plateformes sociales par niche, audience et engagement
Trois dimensions d\'évaluation mesurent des aspects indépendants de la qualité de la recherche : Pertinence (qualité du classement), Couverture (volume de résultats) et Utilité (exhaustivité des données). Celles-ci se combinent pour former le score global de la recherche de personnes par IA.
Méthodologie de notre benchmark de recherche de personnes par IA
Le pipeline d\'évaluation est entièrement automatisé et reproductible. Chaque résultat de chaque plateforme est vérifié par rapport à des sources web en direct—pas de données auto-déclarées, pas de curation manuelle.
Étape 1 : Décomposer la requête. Une requête comme “Ingénieur ML senior dans une startup de série B à Berlin” devient une liste de contrôle structurée : rôle, ancienneté, domaine, étape de l\'entreprise, localisation. Cette décomposition définit les critères de notation pour chaque résultat de la recherche de personnes par IA.
Étape 2 : Vérifier sur le Web. Chaque personne renvoyée par chaque plateforme est vérifiée sur LinkedIn, les sites web d\'entreprise et les profils sociaux. Pas de données auto-déclarées—seulement ce qui peut être confirmé indépendamment en ligne. Cela élimine les biais de plateforme et assure une comparaison équitable pour la recherche de personnes par IA.
Étape 3 : Noter sur trois axes. Pertinence (avez-vous trouvé les bonnes personnes ?), Couverture (combien ?) et Utilité (les données de profil sont-elles réellement utiles ?). Ces trois scores se combinent en un score global : (Pertinence + Couverture + Utilité) / 3.
Ce que nous mesurons pour la recherche de personnes par IA
Pertinence—nDCG@10 pondéré. Mesure si les personnes renvoyées correspondent à la requête et sont correctement classées. Chaque personne est vérifiée sur le web et notée selon des critères explicites. Le score est pondéré pour 10 emplacements—renvoyer moins de résultats est pénalisé. Cela récompense à la fois la précision et le rappel dans les meilleurs résultats de la recherche de personnes par IA.
Couverture—TCR × Rendement. Mesure le nombre de personnes qualifiées trouvées par requête. Combine le taux d\'achèvement des tâches (la plateforme a-t-elle renvoyé des résultats ?) avec le rendement moyen des résultats qualifiés, plafonné à K=10. Cela récompense à la fois la fiabilité et le volume de résultats pertinents.
Utilité—(C + E + A) / 3. Mesure si les données renvoyées sont complètes et exploitables. Moyenne de trois sous-dimensions : exhaustivité structurelle (C), preuves spécifiques à la requête (E) et exploitabilité (A). Un profil avec un nom mais sans e-mail, titre ou entreprise obtient un faible score d\'Utilité même si la personne est pertinente.
Principales conclusions sur la recherche de personnes par IA
Après 476 exécutions de plateforme sur 119 requêtes, plusieurs schémas sont apparus qui révèlent où en est la recherche de personnes par IA aujourd\'hui et où chaque plateforme excelle ou échoue.
- N°1 dans les quatre scénarios. Lessie est la seule plateforme à dominer chaque catégorie—Recrutement, Prospection B2B, Expert / Déterministe et Influenceur / KOL. Aucune autre plateforme ne s\'est classée première dans plus d\'un scénario.
- Taux d\'achèvement de 100 %. Chaque requête a renvoyé des résultats. Aucune autre plateforme n\'a atteint cela—surtout sur les recherches de niche et abstraites où d\'autres n\'ont rien renvoyé. Renvoyer zéro résultat est un mode de défaillance unique aux plateformes à source unique.
- Plus grand écart de pertinence : 70,2 vs 54,3 (+29 %). La différence de qualité de classement est la plus prononcée sur les requêtes multicritères—recherches qui combinent des contraintes de rôle, d\'ancienneté, d\'industrie et de localisation.
- L\'influenceur est l\'écart le plus large. Lessie a obtenu 62,3 au total ; le second a obtenu 43,2. Les plateformes à source unique ont le plus de mal ici car les données d\'influenceur sont fragmentées sur des dizaines de plateformes sociales.
- L\'utilité est la course la plus serrée. L\'exhaustivité des données de profil est la dimension la plus compétitive—toutes les plateformes ont obtenu entre 42,7 et 56,4. C\'est là que l\'industrie a le plus de marge d\'amélioration.
- Le recrutement est le plus compétitif. Trois plateformes ont obtenu plus de 64 au total. C\'est le scénario où les outils existants fonctionnent le mieux—et où les marges sont les plus minces. Les données centrées sur LinkedIn donnent à toutes les plateformes une base plus solide ici.
Open Source : L\'ensemble des données d\'évaluation, la méthodologie de notation et les résultats au niveau de la plateforme sont disponibles pour examen. Nous pensons que des benchmarks transparents font progresser l\'ensemble de l\'industrie de la recherche de personnes par IA.