¿Qué tan buena es la búsqueda de personas con IA en 2026? Creamos un benchmark de código abierto para averiguarlo. 119 consultas del mundo real extraídas de flujos de trabajo reales de profesionales en reclutamiento, ventas y investigación — probadas contra cuatro plataformas: Lessie, Exa, Claude Code y Juicebox. Cada resultado fue verificado de forma independiente contra fuentes web en vivo. Sin datos autoinformados. Sin ejemplos seleccionados a mano.
El resultado: Lessie obtuvo una puntuación general de 65.2, liderando en las cuatro categorías de escenarios. La siguiente plataforma más cercana obtuvo 55. Esta publicación detalla los resultados completos del benchmark — qué medimos, cómo puntuamos y qué revelan los datos sobre el estado de labúsqueda de personas con IA.
Por qué es Importante la Búsqueda de Personas con IA
La búsqueda de personas con IA se está convirtiendo en una infraestructura central para los equipos de reclutamiento, ventas e investigación. Pero hasta ahora, no existía una forma estandarizada de comparar plataformas. Los proveedores autoinforman cifras de precisión que no se pueden verificar. Los estudios de caso seleccionan los mejores resultados. Este benchmark cambia eso — 119 consultas reales, verificación web independiente y un campo de juego equitativo para cada plataforma probada en la búsqueda de personas con IA.
Comparación de Plataformas de Búsqueda de Personas con IA
119 consultas del mundo real, puntuadas de forma independiente mediante verificación web en una escala de 0 – 100. Cada plataforma ejecutó las mismas consultas bajo condiciones idénticas. Las puntuaciones se promedian en tres dimensiones: Relevancia, Cobertura y Utilidad. Esto proporciona una visión clara de la eficacia de cada herramienta de búsqueda de personas con IA.
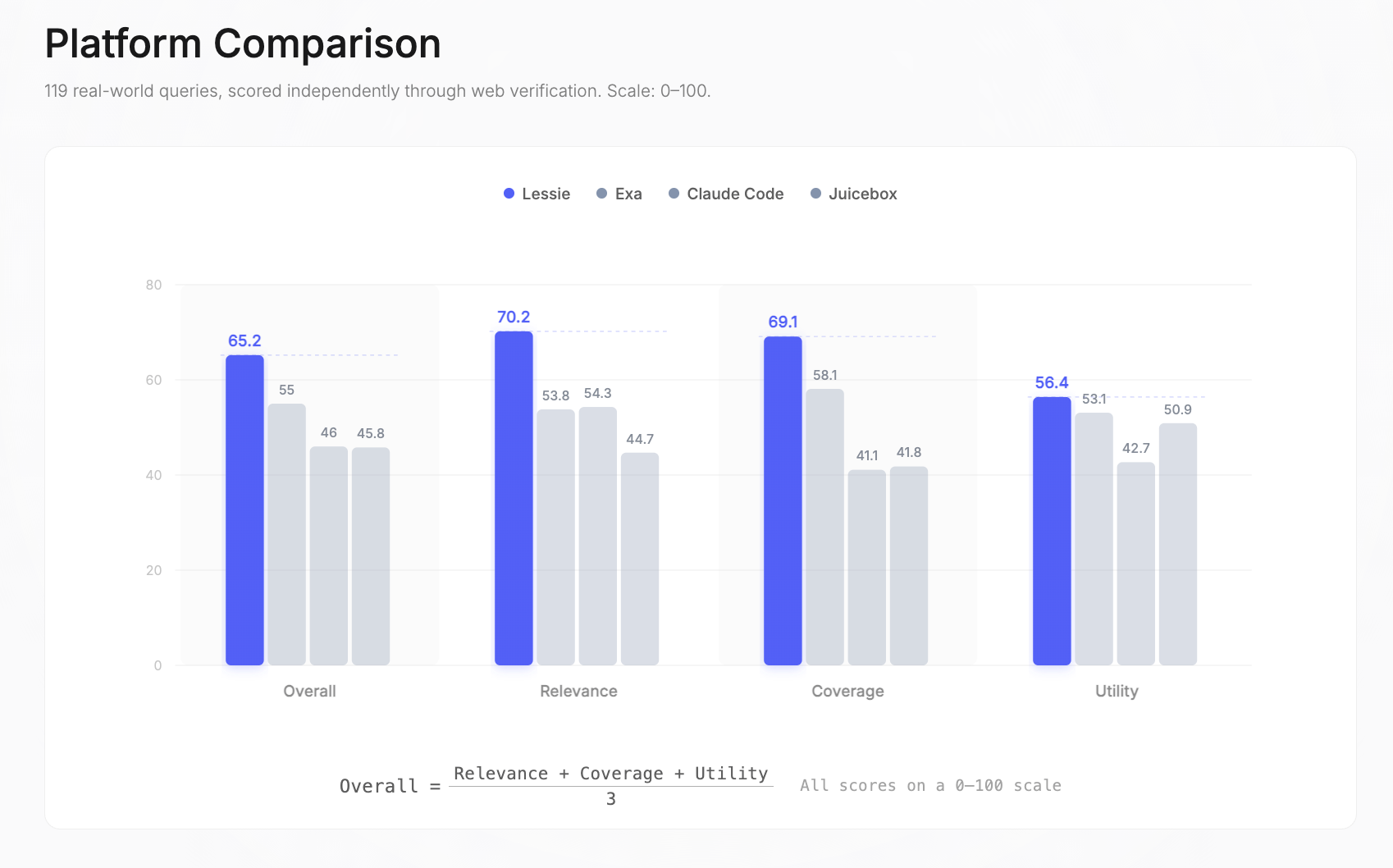
Puntuaciones generales: Lessie 65.2 | Exa 55 | Claude Code 46 | Juicebox 45.8. La puntuación general es el promedio simple de Relevancia, Cobertura y Utilidad — cada una medida de forma independiente en una escala de 0 – 100. Estos resultados demuestran la superioridad de Lessie en la búsqueda de personas con IA.
Desglosándolo por dimensión: Lessie lideró en Relevancia (70.2 vs. 54.3 para el siguiente mejor), Cobertura (69.1 vs. 58.1) y Utilidad (56.4 vs. 53.1). La mayor brecha fue en Relevancia —una ventaja del +29% sobre el segundo lugar — lo que significa que Lessie devolvió consistentemente a las personas adecuadas, correctamente clasificadas, en diversos tipos de consultas de búsqueda de personas con IA.
Rendimiento por Escenario en la Búsqueda de Personas con IA
El benchmark cubre cuatro casos de uso del mundo real donde la búsqueda de personas con IA crea valor empresarial. Cada escenario refleja un flujo de trabajo distinto: diferentes fuentes de datos, diferente complejidad de criterios y diferentes definiciones de un resultado “bueno”.
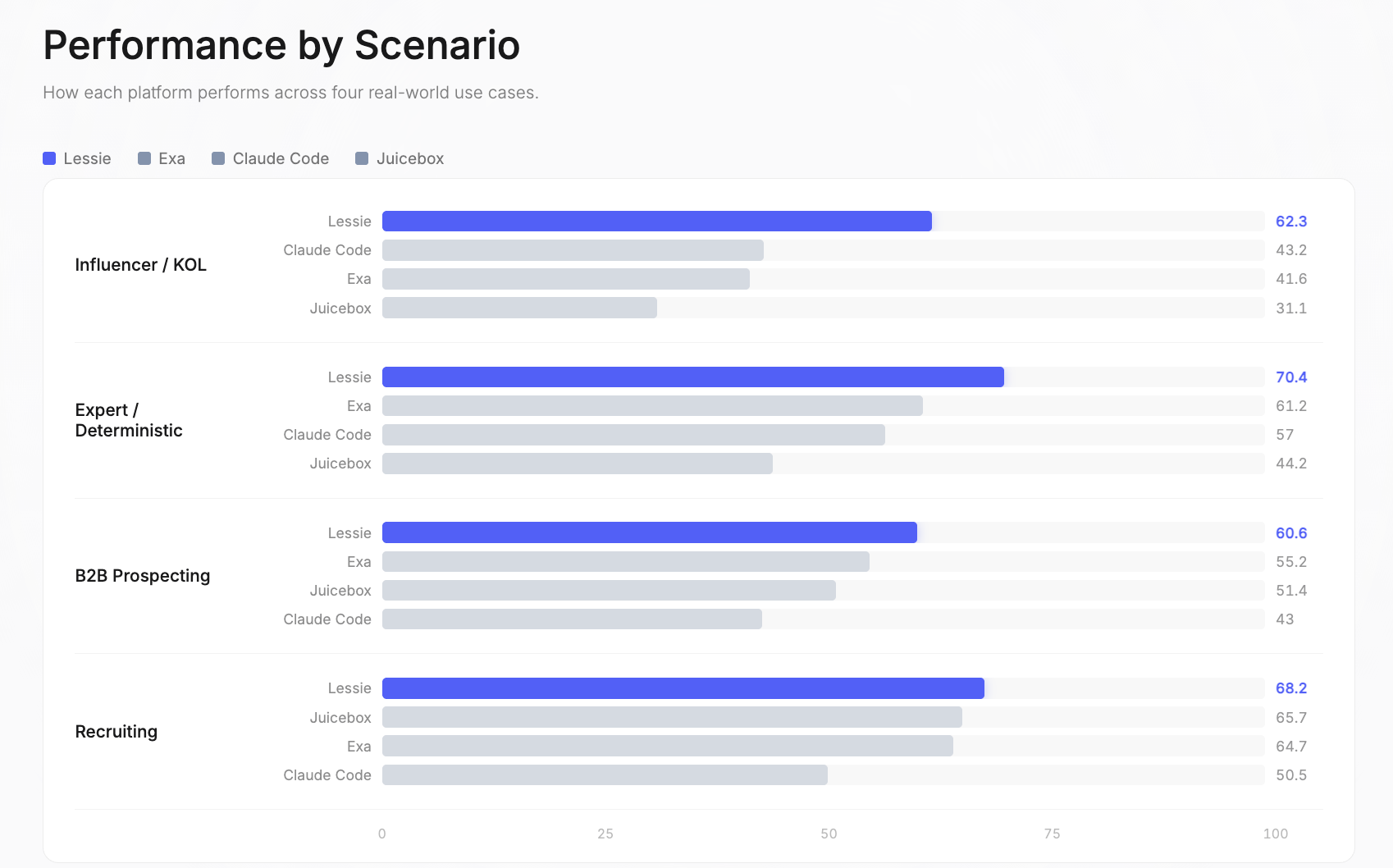
Influencer / KOL: Lessie 62.3 | Claude Code 43.2 | Exa 41.6 | Juicebox 31.1. Esta fue la brecha de rendimiento más amplia en todo el benchmark. Las plataformas de una sola fuente tienen más dificultades aquí porque los influencers existen en plataformas sociales fragmentadas — Instagram, TikTok, YouTube, Twitter, podcasts, newsletters — y ninguna base de datos única los cubre a todos. Lessie destaca en esta faceta de la búsqueda de personas con IA.
Experto / Determinista: Lessie 70.4 | Exa 61.2 | Claude Code 57 | Juicebox 44.2. Estas consultas tienen respuestas correctas verificables o buscan expertos específicos en un dominio. La estrategia de búsqueda híbrida de Lessie — que combina bases de datos estructuradas con investigación web en vivo — demostró ser la más efectiva para encontrar a las personas exactas. Un punto fuerte en la búsqueda de personas con IA.
Prospección B2B: Lessie 60.6 | Exa 55.2 | Juicebox 51.4 | Claude Code 43. Encontrar tomadores de decisiones en empresas objetivo es el caso de uso más común de la búsqueda de personas con IA. La ventaja de Lessie proviene de la referencia cruzada de múltiples fuentes de datos para verificar roles actuales e información de contacto.
Reclutamiento: Lessie 68.2 | Juicebox 65.7 | Exa 64.7 | Claude Code 50.5. Este fue el escenario más competitivo — tres plataformas obtuvieron más de 64 en general. Las consultas de reclutamiento se benefician de las bases de datos centradas en LinkedIn, a las que acceden todas las plataformas. Los márgenes aquí son los más estrechos del benchmark para la búsqueda de personas con IA.
Análisis Detallado por Escenario
Cada puntuación de escenario se desglosa en tres dimensiones independientes: Relevancia (¿encontraste a las personas adecuadas?), Cobertura (¿cuántos resultados calificados?) y Utilidad (¿los datos devueltos son accionables?). Aquí está el desglose detallado de la búsqueda de personas con IA.
Influencer / KOL — Encontrar creadores de contenido en plataformas sociales
- Lessie: Relevancia 65.2, Cobertura 62.8, Utilidad 58.9 — 100% tasa de finalización
- Exa: 89.7% del rendimiento de Lessie
- Claude Code: 82.8% del rendimiento de Lessie
- Juicebox: 79.3% del rendimiento de Lessie
Experto / Determinista — Consultas con respuestas verificables o expertos específicos en un dominio
- Lessie: Relevancia 79, Cobertura 75.2, Utilidad 57.1 — 100% tasa de finalización
- Exa: 96.4% del rendimiento de Lessie
- Claude Code: 100% de tasa de finalización pero puntuaciones generales más bajas
- Juicebox: 71.4% del rendimiento de Lessie
Prospección B2B — Encontrar tomadores de decisiones en empresas objetivo
- Lessie: Relevancia 62.8, Cobertura 63.5, Utilidad 55.5 — 100% tasa de finalización
- Exa: 100% de tasa de finalización, cerca en Cobertura
- Juicebox: 84.4% del rendimiento de Lessie
- Claude Code: 75% de tasa de finalización — la más baja en esta categoría
Reclutamiento — Encontrar candidatos con habilidades, experiencia y ubicación específicas
- Lessie: Relevancia 74.8, Cobertura 75.6, Utilidad 54.3 — 100% tasa de finalización
- Exa, Juicebox: ambas con 100% de tasa de finalización
- Claude Code: 90% de tasa de finalización
- El reclutamiento tuvo las puntuaciones absolutas más altas en todas las plataformas — este es el caso de uso más maduro para la búsqueda de personas con IA
Conjunto de Datos de Evaluación
El benchmark utiliza 119 consultas curadas de flujos de trabajo reales de profesionales en reclutamiento, ventas e investigación. Estos no son casos de prueba sintéticos — reflejan las búsquedas reales que realizan los profesionales cuando buscan personas. El conjunto de datos es multilingüe (inglés, portugués, español, holandés) y está impulsado por profesionales, lo que lo hace ideal para evaluar la búsqueda de personas con IA.
- Reclutamiento (30 consultas): Encontrar candidatos con habilidades específicas, niveles de experiencia y ubicaciones
- Prospección B2B (32 consultas): Identificar tomadores de decisiones en empresas objetivo para el alcance de ventas
- Experto / Determinista (28 consultas): Consultas con respuestas correctas verificables o que buscan expertos específicos en un dominio
- Influencer / KOL (29 consultas): Encontrar creadores de contenido en plataformas sociales por nicho, audiencia y engagement
Tres dimensiones de evaluación miden aspectos independientes de la calidad de la búsqueda: Relevancia (calidad de clasificación), Cobertura (volumen de resultados) y Utilidad (integridad de los datos). Estas se combinan en la puntuación general, un factor clave en la búsqueda de personas con IA.
Metodología de la Búsqueda de Personas con IA
El pipeline de evaluación está completamente automatizado y es reproducible. Cada resultado de cada plataforma se verifica contra fuentes web en vivo — sin datos autoinformados, sin curación manual. Esto asegura la fiabilidad de la búsqueda de personas con IA.
Paso 1: Descomponer la Consulta. Una consulta como “Ingeniero Senior de ML en una startup Serie B en Berlín” se convierte en una lista de verificación estructurada: rol, antigüedad, dominio, etapa de la empresa, ubicación. Esta descomposición define los criterios de calificación para cada resultado en la búsqueda de personas con IA.
Paso 2: Verificar contra la Web. Cada persona devuelta por cada plataforma se verifica contra LinkedIn, sitios web de empresas y perfiles sociales. Sin datos autoinformados — solo lo que se puede confirmar de forma independiente en línea. Esto elimina el sesgo de la plataforma y asegura una comparación justa en la búsqueda de personas con IA.
Paso 3: Puntuar en Tres Ejes. Relevancia (¿encontraste a las personas adecuadas?), Cobertura (¿cuántos?) y Utilidad (¿los datos del perfil son realmente útiles?). Estas tres puntuaciones se combinan en una puntuación general: (Relevancia + Cobertura + Utilidad) / 3.
Qué Medimos en la Búsqueda de Personas con IA
Relevancia — nDCG@10 Relleno. Mide si las personas devueltas coinciden con la consulta y están correctamente clasificadas. Cada persona se verifica en la web y se califica según criterios explícitos. La puntuación se rellena a 10 ranuras — devolver menos resultados se penaliza. Esto recompensa tanto la precisión como la recuperación en los resultados principales de la búsqueda de personas con IA.
Cobertura — TCR × Rendimiento. Mide cuántas personas calificadas se encuentran por consulta. Combina la tasa de finalización de la tarea (¿la plataforma devolvió algún resultado en absoluto?) con el rendimiento promedio de resultados calificados, limitado a K=10. Esto recompensa tanto la fiabilidad como el volumen de resultados relevantes en la búsqueda de personas con IA.
Utilidad — (C + E + A) / 3. Mide si los datos devueltos son completos y accionables. Promedia tres subdimensiones: integridad estructural (C), evidencia específica de la consulta (E) y accionabilidad (A). Un perfil con un nombre pero sin correo electrónico, título o empresa obtiene una puntuación baja en Utilidad, incluso si la persona es relevante para la búsqueda de personas con IA.
Hallazgos Clave sobre la Búsqueda de Personas con IA
Después de 476 ejecuciones de plataforma en 119 consultas, surgieron varios patrones que revelan dónde se encuentra la búsqueda de personas con IA hoy y dónde cada plataforma sobresale o se queda corta.
- #1 en los Cuatro Escenarios. Lessie es la única plataforma que lidera en todas las categorías — Reclutamiento, Prospección B2B, Experto / Determinista e Influencer / KOL. Ninguna otra plataforma ocupó el primer lugar en más de un escenario de búsqueda de personas con IA.
- Tasa de Finalización del 100%. Cada consulta arrojó resultados. Ninguna otra plataforma logró esto — especialmente en búsquedas de nicho y abstractas donde otras no devolvieron nada. Devolver cero resultados es un modo de fallo único de las plataformas de una sola fuente en la búsqueda de personas con IA.
- Mayor Brecha de Relevancia: 70.2 vs. 54.3 (+29%). La diferencia en la calidad de clasificación es más pronunciada en consultas multicriterio — búsquedas que combinan restricciones de rol, antigüedad, industria y ubicación en la búsqueda de personas con IA.
- Influencer es la Brecha más Amplia. Lessie obtuvo 62.3 en general; el segundo lugar obtuvo 43.2. Las plataformas de una sola fuente tienen más dificultades aquí porque los datos de influencers están fragmentados en docenas de plataformas sociales, lo que Lessie aborda eficazmente en la búsqueda de personas con IA.
- La Utilidad es la Carrera más Reñida. La integridad de los datos del perfil es la dimensión más competitiva — todas las plataformas obtuvieron entre 42.7 y 56.4. Aquí es donde la industria tiene más margen de mejora en la búsqueda de personas con IA.
- El Reclutamiento es el más Competitivo. Tres plataformas obtuvieron más de 64 en general. Este es el escenario donde las herramientas existentes funcionan mejor — y donde los márgenes son más estrechos. Los datos centrados en LinkedIn dan a todas las plataformas una base más sólida aquí en la búsqueda de personas con IA.
Código Abierto: El conjunto de datos de evaluación completo, la metodología de puntuación y los resultados a nivel de plataforma están disponibles para su revisión. Creemos que los benchmarks transparentes impulsan a toda la industria de la búsqueda de personas con IA.