2026年AI人物搜尋的表現如何?我們建立了一個開源基準測試來找出答案。119個真實世界的查詢,來自招聘、銷售和研究領域的實際從業者工作流程——針對四個平台進行測試:Lessie、Exa、Claude Code和Juicebox。每個結果都經過獨立的網路來源驗證。沒有自我報告的數據。沒有精挑細選的範例。
結果:Lessie總體得分為65.2分,在所有四個情境類別中均領先。次優平台得分為55分。這篇文章將詳細介紹完整的基準測試結果——我們測量了什麼、如何評分,以及數據揭示了AI人物搜尋的現狀。
為何AI人物搜尋基準測試如此重要
AI人物搜尋正成為招聘、銷售和研究團隊的核心基礎設施。但到目前為止,還沒有標準化的方法來比較各個平台。供應商自我報告的準確性數據無法驗證。案例研究只挑選最佳結果。這個AI人物搜尋基準測試改變了這一點——119個真實查詢、獨立的網路驗證,以及所有測試平台的公平競爭環境。
平台比較
119個真實世界的查詢,透過網路驗證獨立評分,範圍為0–100分。每個平台在相同條件下執行相同的查詢。分數是相關性、覆蓋率和實用性三個維度的平均值。
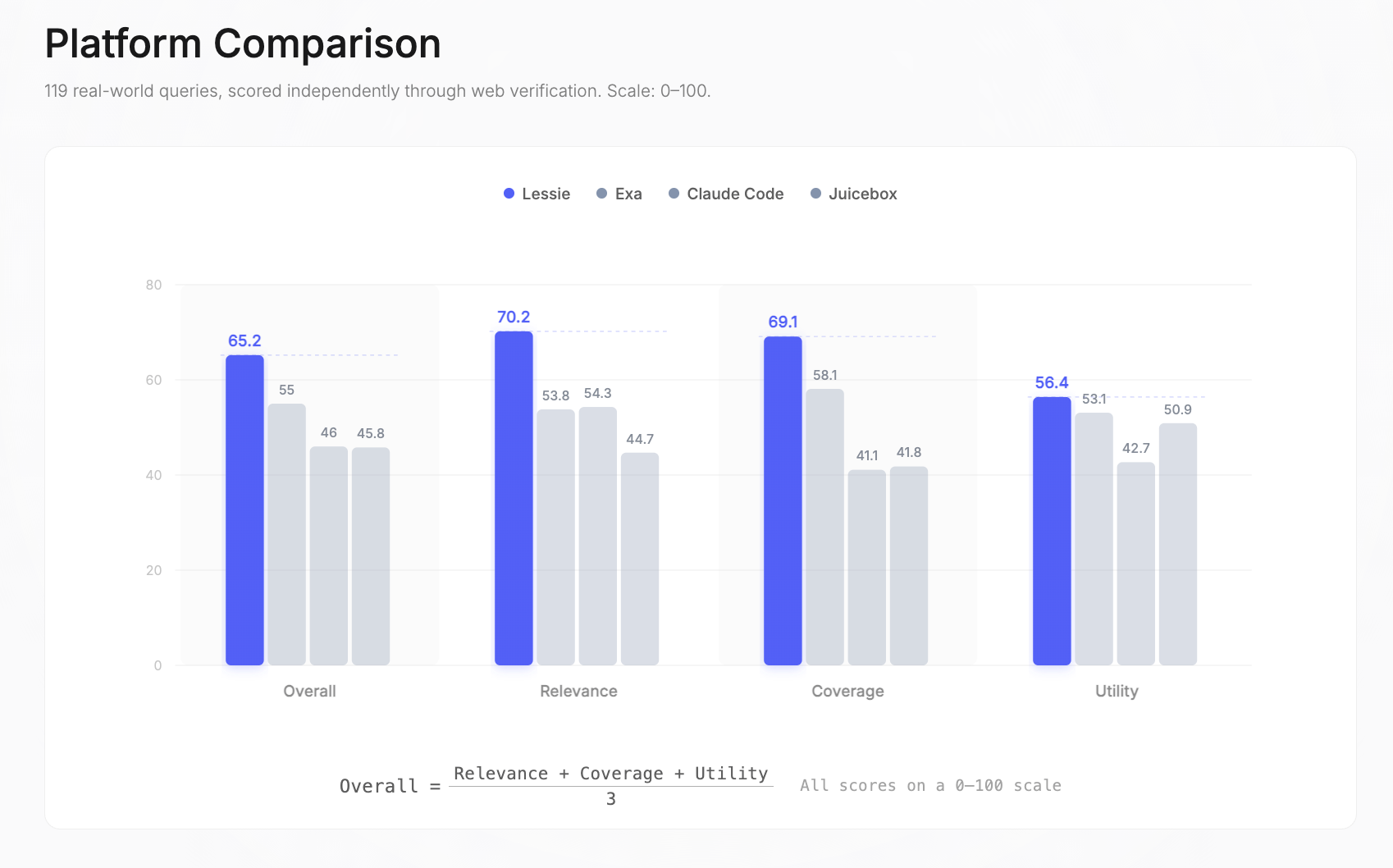
總體得分: Lessie 65.2 | Exa 55 | Claude Code 46 | Juicebox 45.8。總體得分是相關性、覆蓋率和實用性的簡單平均值——每個維度都獨立地以0–100分進行測量。
按維度細分:Lessie在相關性(70.2分,次優為54.3分)、覆蓋率(69.1分,次優為58.1分)和實用性(56.4分,次優為53.1分)方面領先。最大的差距在於相關性——比亞軍高出29%的優勢——這意味著Lessie始終如一地返回正確的人物,並在各種查詢類型中正確排名。
按情境劃分的AI人物搜尋表現
該基準測試涵蓋了四個AI人物搜尋能創造商業價值的真實用例。每個情境都反映了獨特的工作流程:不同的數據源、不同的標準複雜性,以及對「好」結果的不同定義。
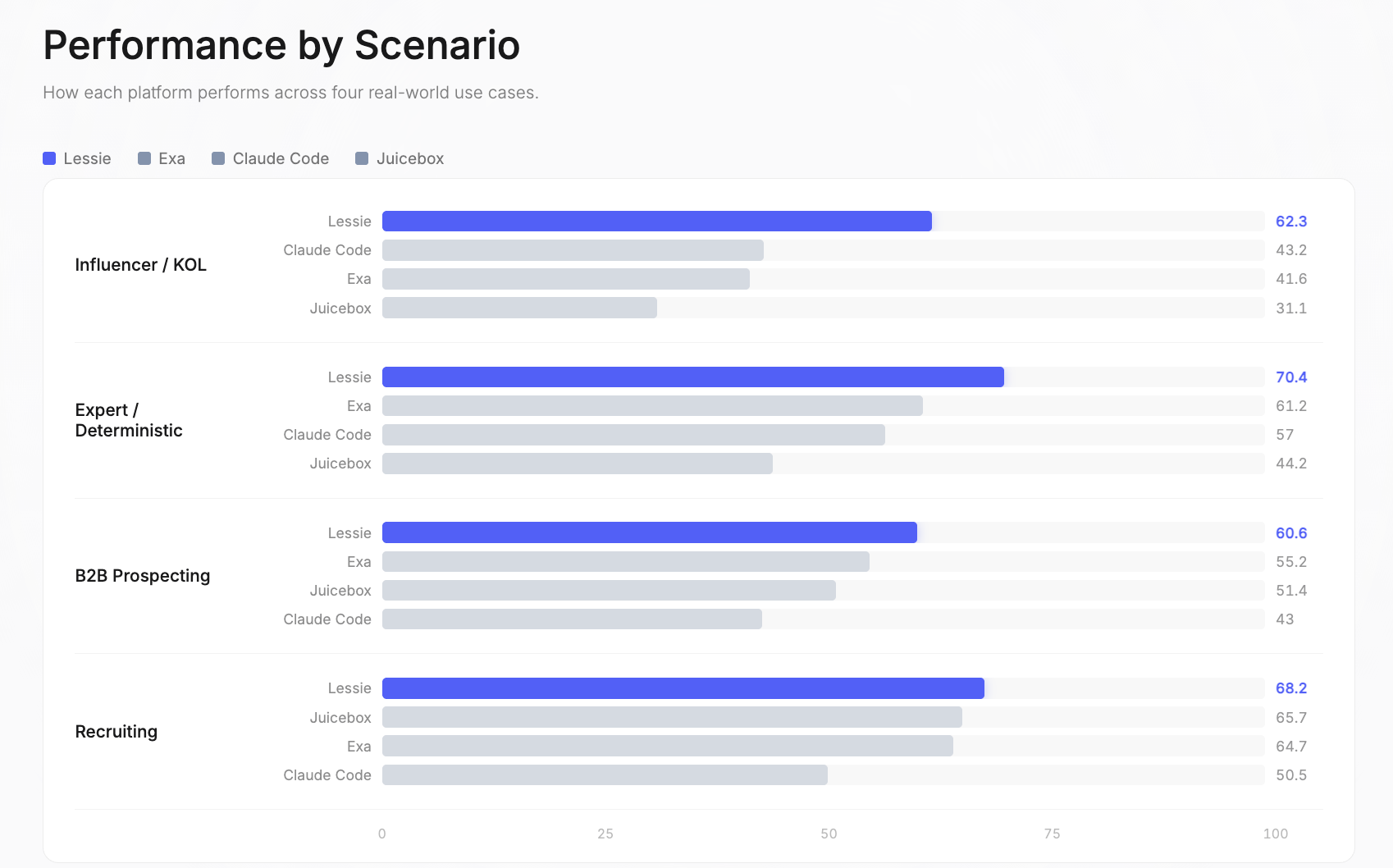
網紅 / KOL: Lessie 62.3 | Claude Code 43.2 | Exa 41.6 | Juicebox 31.1。這是整個基準測試中表現差距最大的一項。單一來源平台在這裡表現最差,因為網紅存在於分散的社交平台——Instagram、TikTok、YouTube、Twitter、播客、新聞通訊——沒有單一資料庫能涵蓋所有這些平台。Lessie的AI人物搜尋能力在此情境中表現卓越。
專家 / 確定性: Lessie 70.4 | Exa 61.2 | Claude Code 57 | Juicebox 44.2。這些查詢具有可驗證的正確答案或尋求特定的領域專家。Lessie的混合搜尋策略——結合結構化資料庫和即時網路研究——被證明在尋找確切的正確人物方面最有效。這也體現了Lessie在AI人物搜尋方面的優勢。
B2B潛在客戶開發: Lessie 60.6 | Exa 55.2 | Juicebox 51.4 | Claude Code 43。在目標公司中尋找決策者是最常見的AI人物搜尋用例。Lessie的優勢來自於交叉參考多個數據源以驗證當前職位和聯繫資訊。
招聘: Lessie 68.2 | Juicebox 65.7 | Exa 64.7 | Claude Code 50.5。這是競爭最激烈的情境——三個平台總體得分都超過64分。招聘查詢受益於以LinkedIn為中心的資料庫,所有平台都可以訪問。這裡的差距是基準測試中最微小的。Lessie的AI人物搜尋在招聘領域依然領先。
情境深度分析
每個情境得分都分解為三個獨立維度:相關性(您找到正確的人了嗎?)、覆蓋率(有多少合格結果?)和實用性(返回的數據是否可操作?)。以下是詳細的細分。
網紅 / KOL——在社交平台尋找內容創作者
- Lessie: 相關性 65.2,覆蓋率 62.8,實用性 58.9——100%完成率
- Exa:Lessie表現的89.7%
- Claude Code:Lessie表現的82.8%
- Juicebox:Lessie表現的79.3%
專家 / 確定性——具有可驗證答案或尋求特定領域專家的查詢
- Lessie: 相關性 79,覆蓋率 75.2,實用性 57.1——100%完成率
- Exa:Lessie表現的96.4%
- Claude Code:100%完成率但總體得分較低
- Juicebox:Lessie表現的71.4%
B2B潛在客戶開發——在目標公司尋找決策者
- Lessie: 相關性 62.8,覆蓋率 63.5,實用性 55.5——100%完成率
- Exa:100%完成率,覆蓋率接近
- Juicebox:Lessie表現的84.4%
- Claude Code:75%完成率——此類別中最低
招聘——尋找具有特定技能、經驗和地點的候選人
- Lessie: 相關性 74.8,覆蓋率 75.6,實用性 54.3——100%完成率
- Exa, Juicebox:均為100%完成率
- Claude Code:90%完成率
- 招聘在所有平台中獲得的絕對分數最高——這是AI人物搜尋最成熟的用例
評估數據集
該基準測試使用了119個查詢,這些查詢是從招聘、銷售和研究領域的實際從業者工作流程中精心策劃的。這些不是合成測試案例——它們反映了專業人士在尋找人物時實際執行的搜尋。該數據集是多語言的(英語、葡萄牙語、西班牙語、荷蘭語),並由從業者驅動。
- 招聘(30個查詢): 尋找具有特定技能、經驗水平和地點的候選人
- B2B潛在客戶開發(32個查詢): 識別目標公司的決策者以進行銷售推廣
- 專家 / 確定性(28個查詢): 具有可驗證正確答案或尋求特定領域專家的查詢
- 網紅 / KOL(29個查詢): 根據利基、受眾和參與度在社交平台尋找內容創作者
三個評估維度衡量搜尋品質的獨立方面:相關性(排名品質)、覆蓋率(結果數量)和實用性(數據完整性)。這些結合起來構成總體得分。Lessie的AI人物搜尋在這些維度上表現出色。
AI人物搜尋基準測試方法論
評估流程是全自動且可重現的。每個平台的所有結果都經過即時網路來源的驗證——沒有自我報告的數據,沒有手動策劃。
步驟1:分解查詢。 像「柏林B輪新創公司的資深機器學習工程師」這樣的查詢會變成一個結構化的清單:職位、資歷、領域、公司階段、地點。這種分解定義了每個結果的評分標準。
步驟2:透過網路驗證。 每個平台返回的每個人物都會與LinkedIn、公司網站和社交資料進行核對。沒有自我報告的數據——只有可以在線上獨立確認的數據。這消除了平台偏見,確保了公平比較。這是AI人物搜尋準確性的關鍵。
步驟3:在三個軸上評分。 相關性(您找到正確的人了嗎?)、覆蓋率(有多少?)和實用性(個人資料數據是否真的有用?)。這三個分數結合為一個總體得分:(相關性 + 覆蓋率 + 實用性)/ 3。
我們測量什麼
相關性——加權nDCG@10。 衡量返回的人物是否符合查詢並正確排名。每個人物都經過網路驗證並根據明確標準進行評分。分數被填充到10個位置——返回較少結果會受到懲罰。這獎勵了頂部結果的精確度和召回率。
覆蓋率——TCR × 產出。 衡量每個查詢找到的合格人數。結合任務完成率(平台是否返回了任何結果?)和平均合格結果產出,上限為K=10。這獎勵了相關結果的可靠性和數量。
實用性——(C + E + A) / 3。 衡量返回的數據是否完整且可操作。平均三個子維度:結構完整性(C)、查詢特定證據(E)和可操作性(A)。一個只有姓名但沒有電子郵件、職稱或公司的個人資料,即使該人物相關,其實用性得分也會很低。
主要發現
在119個查詢的476次平台執行後,出現了幾種模式,揭示了當今AI人物搜尋的現狀以及每個平台的優勢或不足。
- 在所有四個情境中排名第一。 Lessie是唯一在每個類別中都領先的平台——招聘、B2B潛在客戶開發、專家/確定性搜尋和網紅/KOL搜尋。沒有其他平台在一個以上的情境中排名第一。
- 100%完成率。 每個查詢都返回了結果。沒有其他平台達到這一點——尤其是在其他平台沒有返回任何結果的利基和抽象搜尋中。返回零結果是單一來源平台獨有的失敗模式。
- 最大的相關性差距:70.2 vs. 54.3 (+29%)。 排名品質差異在多標準查詢上最為明顯——結合了職位、資歷、行業和地點限制的搜尋。
- 網紅是差距最大的。 Lessie總體得分62.3;亞軍得分43.2。單一來源平台在這裡表現最差,因為網紅數據分散在數十個社交平台中。Lessie的AI人物搜尋在網紅發現方面表現卓越。
- 實用性是競爭最激烈的。 個人資料數據完整性是競爭最激烈的維度——所有平台得分都在42.7到56.4之間。這是該行業最有改進空間的地方。
- 招聘是最具競爭力的。 三個平台總體得分都超過64分。這是現有工具表現最佳的情境——也是差距最微小的。以LinkedIn為中心的數據為所有平台提供了更強的基準。Lessie的AI人物搜尋在招聘領域依然保持領先。
開源: 完整的評估數據集、評分方法論和平台級結果均可供審查。我們相信透明的基準測試能推動整個行業向前發展。